

Data analysts play a vital role in today’s data-driven world, providing crucial insights that benefit decision-making processes. For those with a knack for numbers and a passion for uncovering patterns, a career as a data analyst can be both fulfilling and lucrative – it can also be a stepping stone towards other careers in data. While a data analyst focuses on data preparation and visualisation, an AI engineer specialises in creating AI solutions, a machine learning (ML) engineer concentrates on implementing ML models, and a data scientist combines elements of data analysis and ML to derive insights and predictions from data.
Tools, Skills, and Techniques of a Data Analyst
Excel Mastery. Unlocks a powerful toolbox for data manipulation and analysis. Essential skills include using a vast array of functions for calculations and data transformation. Pivot tables become your secret weapon for summarising and analysing large datasets, while charts and graphs bring your findings to life with visual clarity. Data validation ensures accuracy, and the Analysis ToolPak and Solver provide advanced functionalities for statistical analysis and complex problem-solving. Mastering Excel empowers you to transform raw data into actionable insights.
Advanced SQL. While basic skills handle simple queries, advanced users can go deeper with sorting, aggregation, and the art of JOINs to combine data from multiple tables. Common Table Expressions (CTEs) and subqueries become your allies for crafting complex queries, while aggregate functions summarise vast amounts of data. Window functions add another layer of power, allowing calculations within query results. Mastering Advanced SQL empowers you to extract hidden insights and manage data with unparalleled precision.
Data Visualisation. Crafts impactful data stories. These tools empower you to connect to various data sources, transform raw information into a usable format, and design interactive dashboards and reports. Filters and drilldowns allow users to explore your data from different angles, while calculated fields unlock deeper analysis. Parameters add a final touch of flexibility, letting viewers customise the report to their specific needs. With tools Tableau and Power BI, complex data becomes clear and engaging.
Essential Python. This powerful language excels at data analysis and automation. Libraries like NumPy and Pandas become your foundation for data manipulation and wrangling. Scikit-learn empowers you to build ML models, while SciPy and StatsModels provide a toolkit for in-depth statistical analysis. Python’s ability to interact with APIs and web scrape data expands its reach, and its automation capabilities streamline repetitive tasks. With Essential Python, you have the power to solve complex problems.
Automating the Journey. Data analysts can be masters of efficiency, and their skills translate beautifully into AI. Scripting languages like Ansible and Terraform automate repetitive tasks. Imagine streamlining the process of training and deploying AI models – a skill that directly benefits the AI development pipeline. This proficiency in automation showcases the valuable foundation data analysts provide for building and maintaining AI systems.
Developing ML Expertise. Transitioning from data analysis to AI involves building on your existing skills to develop ML expertise. As a data analyst, you may start with basic predictive models. This knowledge is expanded in AI to include deep learning and advanced ML algorithms. Also, skills in statistical analysis and visualisation help in evaluating the performance of AI models.
Growing Your AI Skills
Becoming an AI engineer requires building on a data analysis foundation to focus on advanced skills such as:
- Deep Learning. Learning frameworks like TensorFlow and PyTorch to build and train neural networks.
- Natural Language Processing (NLP). Techniques for processing and analysing large amounts of natural language data.
- AI Ethics and Fairness. Understanding the ethical implications of AI and ensuring models are fair and unbiased.
- Big Data Technologies. Using tools like Hadoop and Spark for handling large-scale data is essential for AI applications.
The Evolution of a Data Analyst: Career Opportunities
Data analysis is a springboard to AI engineering. Businesses crave talent that bridges the data-AI gap. Your data analyst skills provide the foundation (understanding data sources and transformations) to excel in AI. As you master ML, you can progress to roles like:
- AI Engineer. Works on integrating AI solutions into products and services. They work with AI frameworks like TensorFlow and PyTorch, ensuring that AI models are incorporated into products and services in a fair and unbiased manner.
- ML Engineer. Focuses on designing and implementing ML models. They focus on preprocessing data, evaluating model performance, and collaborating with data scientists and engineers to bring models into production. They need strong programming skills and experience with big data tools and ML algorithms.
- Data Scientist. Bridges the gap between data analysis and AI, often involved in both data preparation and model development. They perform exploratory data analysis, develop predictive models, and collaborate with cross-functional teams to solve complex business problems. Their role requires a comprehensive understanding of both data analysis and ML, as well as strong programming and data visualisation skills.
Conclusion
Hone your data expertise and unlock a future in AI! Mastering in-demand skills like Excel, SQL, Python, and data visualisation tools will equip you to excel as a data analyst. Your data wrangling skills will be invaluable as you explore ML and advanced algorithms. Also, your existing BI knowledge translates seamlessly into building and evaluating AI models. Remember, the data landscape is constantly evolving, so continue to learn to stay at the forefront of this dynamic field. By combining your data skills with a passion for AI, you’ll be well-positioned to tackle complex challenges and shape the future of AI.


AI tools have become a game-changer for the technology industry, enhancing developer productivity and software quality. Leveraging advanced machine learning models and natural language processing, these tools offer a wide range of capabilities, from code completion to generating entire blocks of code, significantly reducing the cognitive load on developers. AI-powered tools not only accelerate the coding process but also ensure higher code quality and consistency, aligning seamlessly with modern development practices. Organisations are reaping the benefits of these tools, which have transformed the software development lifecycle.

Impact on Developer Productivity
AI tools are becoming an indispensable part of software development owing to their:
- Speed and Efficiency. AI-powered tools provide real-time code suggestions, which dramatically reduces the time developers spend writing boilerplate code and debugging. For example, Tabnine can suggest complete blocks of code based on the comments or a partial code snippet, which accelerates the development process.
- Quality and Accuracy. By analysing vast datasets of code, AI tools can offer not only syntactically correct but also contextually appropriate code suggestions. This capability reduces bugs and improves the overall quality of the software.
- Learning and Collaboration. AI tools also serve as learning aids for developers by exposing them to new or better coding practices and patterns. Novice developers, in particular, can benefit from real-time feedback and examples, accelerating their professional growth. These tools can also help maintain consistency in coding standards across teams, fostering better collaboration.
Advantages of Using AI Tools in Development
- Reduced Time to Market. Faster coding and debugging directly contribute to shorter development cycles, enabling organisations to launch products faster. This reduction in time to market is crucial in today’s competitive business environment where speed often translates to a significant market advantage.
- Cost Efficiency. While there is an upfront cost in integrating these AI tools, the overall return on investment (ROI) is enhanced through the reduced need for extensive manual code reviews, decreased dependency on large development teams, and lower maintenance costs due to improved code quality.
- Scalability and Adaptability. AI tools learn and adapt over time, becoming more efficient and aligned with specific team or project needs. This adaptability ensures that the tools remain effective as the complexity of projects increases or as new technologies emerge.
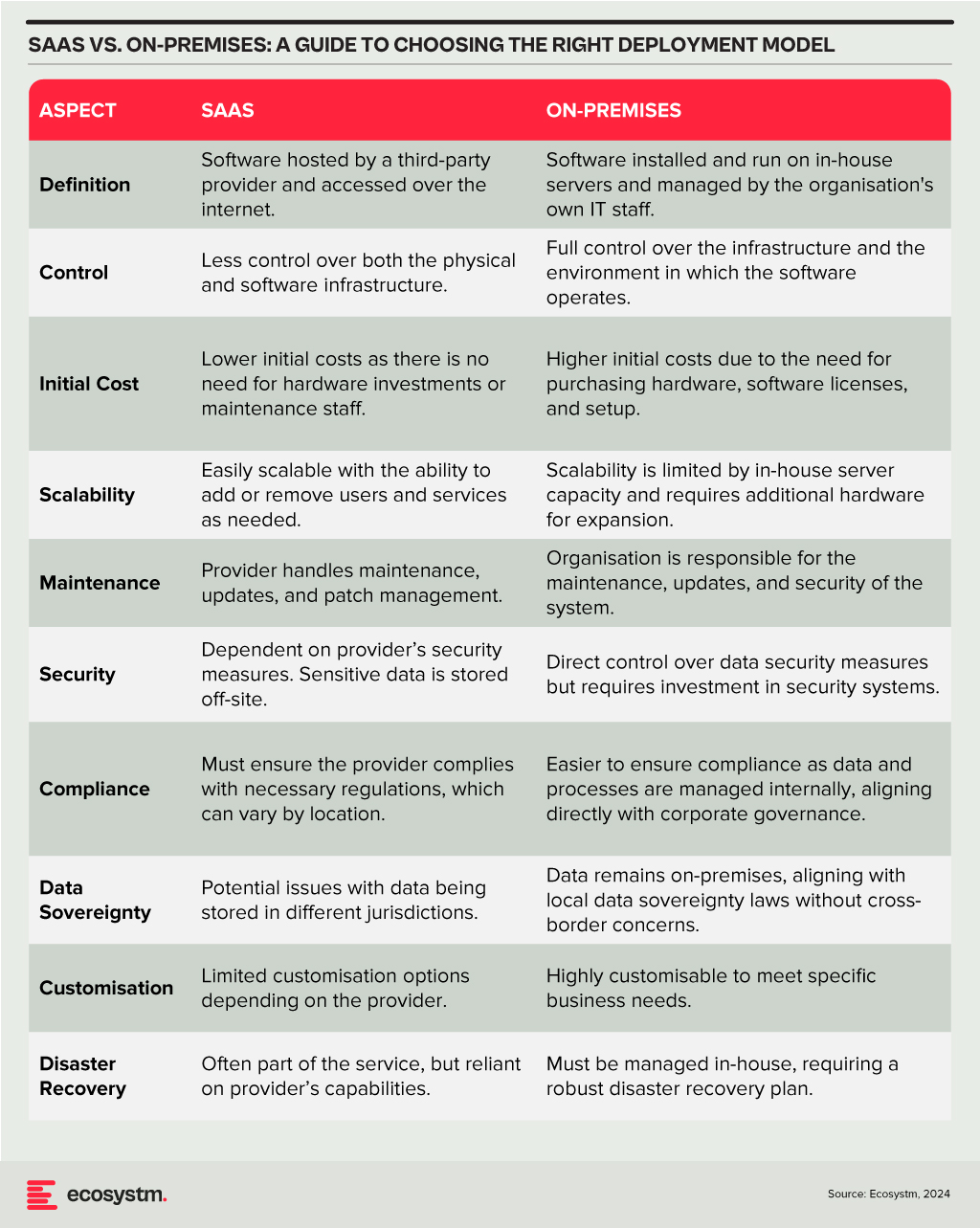
Deployment Models
The choice between SaaS and on-premises deployment models involves a trade-off between control, cost, and flexibility. Organisations need to consider their specific requirements, including the level of control desired over the infrastructure, sensitivity of the data, compliance needs, and available IT resources. A thorough assessment will guide the decision, ensuring that the deployment model chosen aligns with the organisation’s operational objectives and strategic goals.
Technology teams must consider challenges such as the reliability of generated code, the potential for generating biased or insecure code, and the dependency on external APIs or services. Proper oversight, regular evaluations, and a balanced integration of AI tools with human oversight are recommended to mitigate these risks.
A Roadmap for AI Integration
The strategic integration of AI tools in software development offers a significant opportunity for companies to achieve a competitive edge. By starting with pilot projects, organisations can assess the impact and utility of AI within specific teams. Encouraging continuous training in AI advancements empowers developers to leverage these tools effectively. Regular audits ensure that AI-generated code adheres to security standards and company policies, while feedback mechanisms facilitate the refinement of tool usage and address any emerging issues.
Technology teams have the opportunity to not only boost operational efficiency but also cultivate a culture of innovation and continuous improvement in their software development practices. As AI technology matures, even more sophisticated tools are expected to emerge, further propelling developer capabilities and software development to new heights.


In my last Ecosystm Insight, I spoke about the importance of data architecture in defining the data flow, data management systems required, the data processing operations, and AI applications. Data Mesh and Data Fabric are both modern architectural approaches designed to address the complexities of managing and accessing data across a large organisation. While they share some commonalities, such as improving data accessibility and governance, they differ significantly in their methodologies and focal points.
Data Mesh
- Philosophy and Focus. Data Mesh is primarily focused on the organisational and architectural approach to decentralise data ownership and governance. It treats data as a product, emphasising the importance of domain-oriented decentralised data ownership and architecture. The core principles of Data Mesh include domain-oriented decentralised data ownership, data as a product, self-serve data infrastructure as a platform, and federated computational governance.
- Implementation. In a Data Mesh, data is managed and owned by domain-specific teams who are responsible for their data products from end to end. This includes ensuring data quality, accessibility, and security. The aim is to enable these teams to provide and consume data as products, improving agility and innovation.
- Use Cases. Data Mesh is particularly effective in large, complex organisations with many independent teams and departments. It’s beneficial when there’s a need for agility and rapid innovation within specific domains or when the centralisation of data management has become a bottleneck.
Data Fabric
- Philosophy and Focus. Data Fabric focuses on creating a unified, integrated layer of data and connectivity across an organisation. It leverages metadata, advanced analytics, and AI to improve data discovery, governance, and integration. Data Fabric aims to provide a comprehensive and coherent data environment that supports a wide range of data management tasks across various platforms and locations.
- Implementation. Data Fabric typically uses advanced tools to automate data discovery, governance, and integration tasks. It creates a seamless environment where data can be easily accessed and shared, regardless of where it resides or what format it is in. This approach relies heavily on metadata to enable intelligent and automated data management practices.
- Use Cases. Data Fabric is ideal for organisations that need to manage large volumes of data across multiple systems and platforms. It is particularly useful for enhancing data accessibility, reducing integration complexity, and supporting data governance at scale. Data Fabric can benefit environments where there’s a need for real-time data access and analysis across diverse data sources.
Both approaches aim to overcome the challenges of data silos and improve data accessibility, but they do so through different methodologies and with different priorities.
Data Mesh and Data Fabric Vendors
The concepts of Data Mesh and Data Fabric are supported by various vendors, each offering tools and platforms designed to facilitate the implementation of these architectures. Here’s an overview of some key players in both spaces:
Data Mesh Vendors
Data Mesh is more of a conceptual approach than a product-specific solution, focusing on organisational structure and data decentralisation. However, several vendors offer tools and platforms that support the principles of Data Mesh, such as domain-driven design, product thinking for data, and self-serve data infrastructure:
- Thoughtworks. As the originator of the Data Mesh concept, Thoughtworks provides consultancy and implementation services to help organisations adopt Data Mesh principles.
- Starburst. Starburst offers a distributed SQL query engine (Starburst Galaxy) that allows querying data across various sources, aligning with the Data Mesh principle of domain-oriented, decentralised data ownership.
- Databricks. Databricks provides a unified analytics platform that supports collaborative data science and analytics, which can be leveraged to build domain-oriented data products in a Data Mesh architecture.
- Snowflake. With its Data Cloud, Snowflake facilitates data sharing and collaboration across organisational boundaries, supporting the Data Mesh approach to data product thinking.
- Collibra. Collibra provides a data intelligence cloud that offers data governance, cataloguing, and privacy management tools essential for the Data Mesh approach. By enabling better data discovery, quality, and policy management, Collibra supports the governance aspect of Data Mesh.
Data Fabric Vendors
Data Fabric solutions often come as more integrated products or platforms, focusing on data integration, management, and governance across a diverse set of systems and environments:
- Informatica. The Informatica Intelligent Data Management Cloud includes features for data integration, quality, governance, and metadata management that are core to a Data Fabric strategy.
- Talend. Talend provides data integration and integrity solutions with strong capabilities in real-time data collection and governance, supporting the automated and comprehensive approach of Data Fabric.
- IBM. IBM’s watsonx.data is a fully integrated data and AI platform that automates the lifecycle of data across multiple clouds and systems, embodying the Data Fabric approach to making data easily accessible and governed.
- TIBCO. TIBCO offers a range of products, including TIBCO Data Virtualization and TIBCO EBX, that support the creation of a Data Fabric by enabling comprehensive data management, integration, and governance.
- NetApp. NetApp has a suite of cloud data services that provide a simple and consistent way to integrate and deliver data across cloud and on-premises environments. NetApp’s Data Fabric is designed to enhance data control, protection, and freedom.
The choice of vendor or tool for either Data Mesh or Data Fabric should be guided by the specific needs, existing technology stack, and strategic goals of the organisation. Many vendors provide a range of capabilities that can support different aspects of both architectures, and the best solution often involves a combination of tools and platforms. Additionally, the technology landscape is rapidly evolving, so it’s wise to stay updated on the latest offerings and how they align with the organisation’s data strategy.

The data architecture outlines how data is managed in an organisation and is crucial for defining the data flow, data management systems required, the data processing operations, and AI applications. Data architects and engineers define data models and structures based on these requirements, supporting initiatives like data science. Before we delve into the right data architecture for your AI journey, let’s talk about the data management options. Technology leaders have the challenge of deciding on a data management system that takes into consideration factors such as current and future data needs, available skills, costs, and scalability. As data strategies become vital to business success, selecting the right data management system is crucial for enabling data-driven decisions and innovation.
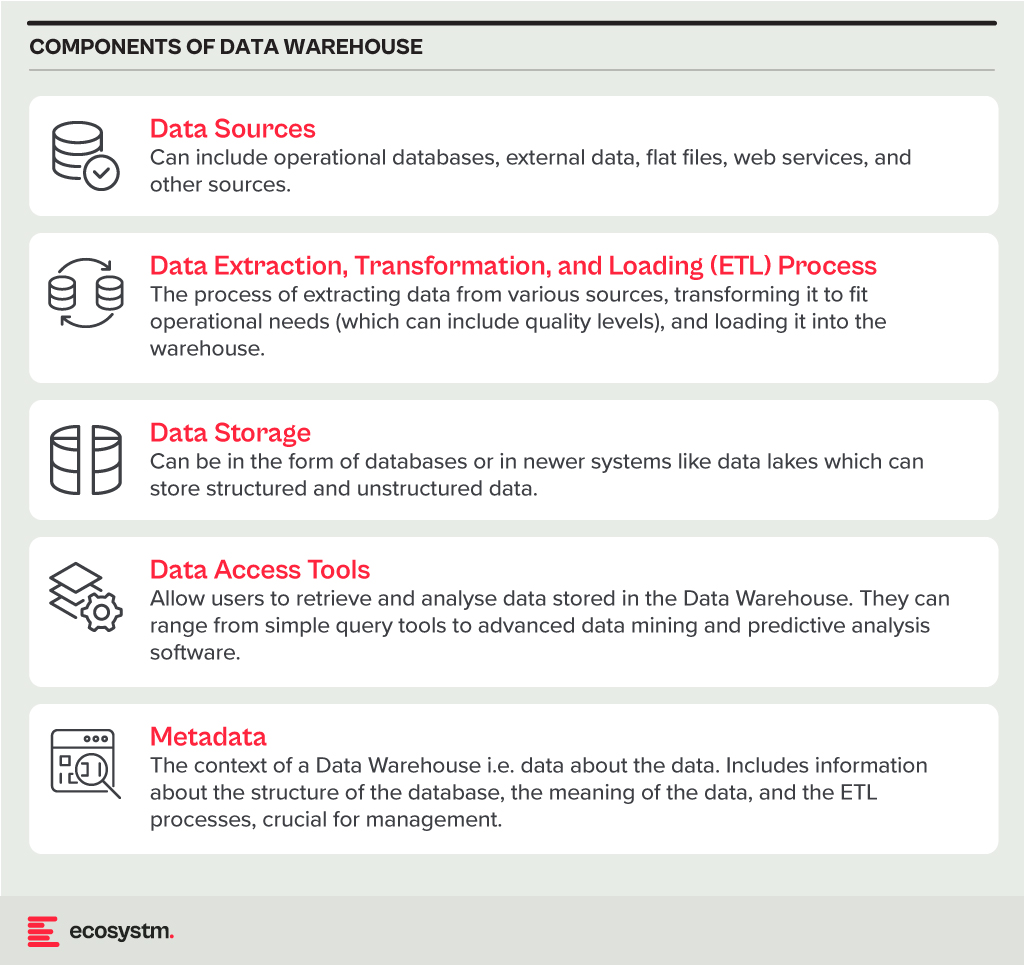
Data Warehouse
A Data Warehouse is a centralised repository that stores vast amounts of data from diverse sources within an organisation. Its main function is to support reporting and data analysis, aiding businesses in making informed decisions. This concept encompasses both data storage and the consolidation and management of data from various sources to offer valuable business insights. Data Warehousing evolves alongside technological advancements, with trends like cloud-based solutions, real-time capabilities, and the integration of AI and machine learning for predictive analytics shaping its future.
Core Characteristics
- Integrated. It integrates data from multiple sources, ensuring consistent definitions and formats. This often includes data cleansing and transformation for analysis suitability.
- Subject-Oriented. Unlike operational databases, which prioritise transaction processing, it is structured around key business subjects like customers, products, and sales. This organisation facilitates complex queries and analysis.
- Non-Volatile. Data in a Data Warehouse is stable; once entered, it is not deleted. Historical data is retained for analysis, allowing for trend identification over time.
- Time-Variant. It retains historical data for trend analysis across various time periods. Each entry is time-stamped, enabling change tracking and trend analysis.
Benefits
- Better Decision Making. Data Warehouses consolidate data from multiple sources, offering a comprehensive business view for improved decision-making.
- Enhanced Data Quality. The ETL process ensures clean and consistent data entry, crucial for accurate analysis.
- Historical Analysis. Storing historical data enables trend analysis over time, informing future strategies.
- Improved Efficiency. Data Warehouses enable swift access and analysis of relevant data, enhancing efficiency and productivity.
Challenges
- Complexity. Designing and implementing a Data Warehouse can be complex and time-consuming.
- Cost. The cost of hardware, software, and specialised personnel can be significant.
- Data Security. Storing large amounts of sensitive data in one place poses security risks, requiring robust security measures.
Data Lake
A Data Lake is a centralised repository for storing, processing, and securing large volumes of structured and unstructured data. Unlike traditional Data Warehouses, which are structured and optimised for analytics with predefined schemas, Data Lakes retain raw data in its native format. This flexibility in data usage and analysis makes them crucial in modern data architecture, particularly in the age of big data and cloud.
Core Characteristics
- Schema-on-Read Approach. This means the data structure is not defined until the data is read for analysis. This offers more flexible data storage compared to the schema-on-write approach of Data Warehouses.
- Support for Multiple Data Types. Data Lakes accommodate diverse data types, including structured (like databases), semi-structured (like JSON, XML files), unstructured (like text and multimedia files), and binary data.
- Scalability. Designed to handle vast amounts of data, Data Lakes can easily scale up or down based on storage needs and computational demands, making them ideal for big data applications.
- Versatility. Data Lakes support various data operations, including batch processing, real-time analytics, machine learning, and data visualisation, providing a versatile platform for data science and analytics.

Benefits
- Flexibility. Data Lakes offer diverse storage formats and a schema-on-read approach for flexible analysis.
- Cost-Effectiveness. Cloud-hosted Data Lakes are cost-effective with scalable storage solutions.
- Advanced Analytics Capabilities. The raw, granular data in Data Lakes is ideal for advanced analytics, machine learning, and AI applications, providing deeper insights than traditional data warehouses.
Challenges
- Complexity and Management. Without proper management, a Data Lake can quickly become a “Data Swamp” where data is disorganised and unusable.
- Data Quality and Governance. Ensuring the quality and governance of data within a Data Lake can be challenging, requiring robust processes and tools.
- Security. Protecting sensitive data within a Data Lake is crucial, requiring comprehensive security measures.
Data Lakehouse
A Data Lakehouse is an innovative data management system that merges the strengths of Data Lakes and Data Warehouses. This hybrid approach strives to offer the adaptability and expansiveness of a Data Lake for housing extensive volumes of raw, unstructured data, while also providing the structured, refined data functionalities typical of a Data Warehouse. By bridging the gap between these two traditional data storage paradigms, Lakehouses enable more efficient data analytics, machine learning, and business intelligence operations across diverse data types and use cases.
Core Characteristics
- Unified Data Management. A Lakehouse streamlines data governance and security by managing both structured and unstructured data on one platform, reducing organizational data silos.
- Schema Flexibility. It supports schema-on-read and schema-on-write, allowing data to be stored and analysed flexibly. Data can be ingested in raw form and structured later or structured at ingestion.
- Scalability and Performance. Lakehouses scale storage and compute resources independently, handling large data volumes and complex analytics without performance compromise.
- Advanced Analytics and Machine Learning Integration. By providing direct access to both raw and processed data on a unified platform, Lakehouses facilitate advanced analytics, real-time analytics, and machine learning.

Benefits
- Versatility in Data Analysis. Lakehouses support diverse data analytics, spanning from traditional BI to advanced machine learning, all within one platform.
- Cost-Effective Scalability. The ability to scale storage and compute independently, often in a cloud environment, makes Lakehouses cost-effective for growing data needs.
- Improved Data Governance. Centralising data management enhances governance, security, and quality across all types of data.
Challenges
- Complexity in Implementation. Designing and implementing a Lakehouse architecture can be complex, requiring expertise in both Data Lakes and Data Warehouses.
- Data Consistency and Quality. Though crucial for reliable analytics, ensuring data consistency and quality across diverse data types and sources can be challenging.
- Governance and Security. Comprehensive data governance and security strategies are required to protect sensitive information and comply with regulations.
The choice between Data Warehouse, Data Lake, or Lakehouse systems is pivotal for businesses in harnessing the power of their data. Each option offers distinct advantages and challenges, requiring careful consideration of organisational needs and goals. By embracing the right data management system, organisations can pave the way for informed decision-making, operational efficiency, and innovation in the digital age.

Historically, data scientists have been the linchpins in the world of AI and machine learning, responsible for everything from data collection and curation to model training and validation. However, as the field matures, we’re witnessing a significant shift towards specialisation, particularly in data engineering and the strategic role of Large Language Models (LLMs) in data curation and labelling. The integration of AI into applications is also reshaping the landscape of software development and application design.
The Growth of Embedded AI
AI is being embedded into applications to enhance user experience, optimise operations, and provide insights that were previously inaccessible. For example, natural language processing (NLP) models are being used to power conversational chatbots for customer service, while machine learning algorithms are analysing user behaviour to customise content feeds on social media platforms. These applications leverage AI to perform complex tasks, such as understanding user intent, predicting future actions, or automating decision-making processes, making AI integration a critical component of modern software development.
This shift towards AI-embedded applications is not only changing the nature of the products and services offered but is also transforming the roles of those who build them. Since the traditional developer may not possess extensive AI skills, the role of data scientists is evolving, moving away from data engineering tasks and increasingly towards direct involvement in development processes.
The Role of LLMs in Data Curation
The emergence of LLMs has introduced a novel approach to handling data curation and processing tasks traditionally performed by data scientists. LLMs, with their profound understanding of natural language and ability to generate human-like text, are increasingly being used to automate aspects of data labelling and curation. This not only speeds up the process but also allows data scientists to focus more on strategic tasks such as model architecture design and hyperparameter tuning.
The accuracy of AI models is directly tied to the quality of the data they’re trained on. Incorrectly labelled data or poorly curated datasets can lead to biased outcomes, mispredictions, and ultimately, the failure of AI projects. The role of data engineers and the use of advanced tools like LLMs in ensuring the integrity of data cannot be overstated.
The Impact on Traditional Developers
Traditional software developers have primarily focused on writing code, debugging, and software maintenance, with a clear emphasis on programming languages, algorithms, and software architecture. However, as applications become more AI-driven, there is a growing need for developers to understand and integrate AI models and algorithms into their applications. This requirement presents a challenge for developers who may not have specialised training in AI or data science. This is seeing an increasing demand for upskilling and cross-disciplinary collaboration to bridge the gap between traditional software development and AI integration.
Clear Role Differentiation: Data Engineering and Data Science
In response to this shift, the role of data scientists is expanding beyond the confines of traditional data engineering and data science, to include more direct involvement in the development of applications and the embedding of AI features and functions.
Data engineering has always been a foundational element of the data scientist’s role, and its importance has increased with the surge in data volume, variety, and velocity. Integrating LLMs into the data collection process represents a cutting-edge approach to automating the curation and labelling of data, streamlining the data management process, and significantly enhancing the efficiency of data utilisation for AI and ML projects.
Accurate data labelling and meticulous curation are paramount to developing models that are both reliable and unbiased. Errors in data labelling or poorly curated datasets can lead to models that make inaccurate predictions or, worse, perpetuate biases. The integration of LLMs into data engineering tasks is facilitating a transformation, freeing them from the burdens of manual data labelling and curation. This has led to a more specialised data scientist role that allocates more time and resources to areas that can create greater impact.
The Evolving Role of Data Scientists
Data scientists, with their deep understanding of AI models and algorithms, are increasingly working alongside developers to embed AI capabilities into applications. This collaboration is essential for ensuring that AI models are effectively integrated, optimised for performance, and aligned with the application’s objectives.
- Model Development and Innovation. With the groundwork of data preparation laid by LLMs, data scientists can focus on developing more sophisticated and accurate AI models, exploring new algorithms, and innovating in AI and ML technologies.
- Strategic Insights and Decision Making. Data scientists can spend more time analysing data and extracting valuable insights that can inform business strategies and decision-making processes.
- Cross-disciplinary Collaboration. This shift also enables data scientists to engage more deeply in interdisciplinary collaboration, working closely with other departments to ensure that AI and ML technologies are effectively integrated into broader business processes and objectives.
- AI Feature Design. Data scientists are playing a crucial role in designing AI-driven features of applications, ensuring that the use of AI adds tangible value to the user experience.
- Model Integration and Optimisation. Data scientists are also involved in integrating AI models into the application architecture, optimising them for efficiency and scalability, and ensuring that they perform effectively in production environments.
- Monitoring and Iteration. Once AI models are deployed, data scientists work on monitoring their performance, interpreting outcomes, and making necessary adjustments. This iterative process ensures that AI functionalities continue to meet user needs and adapt to changing data landscapes.
- Research and Continued Learning. Finally, the transformation allows data scientists to dedicate more time to research and continued learning, staying ahead of the rapidly evolving field of AI and ensuring that their skills and knowledge remain cutting-edge.
Conclusion
The integration of AI into applications is leading to a transformation in the roles within the software development ecosystem. As applications become increasingly AI-driven, the distinction between software development and AI model development is blurring. This convergence needs a more collaborative approach, where traditional developers gain AI literacy and data scientists take on more active roles in application development. The evolution of these roles highlights the interdisciplinary nature of building modern AI-embedded applications and underscores the importance of continuous learning and adaptation in the rapidly advancing field of AI.

AI systems are creating huge amounts of data at a rapid rate. While this flood of information is extremely valuable, it is also difficult to analyse and understand. Organisations need to make sense of these large data sets to derive useful insights and make better decisions. Data visualisation plays a pivotal role in the interpretation of complex data, making it accessible, understandable, and actionable. Well-designed visualisation can translate complex, high-dimensional data into intuitive, visually appealing representations, helping stakeholders to understand patterns, trends, and anomalies that would otherwise be challenging to recognise.
There are some data visualisation methods that you are using already; and some that you definitely should master as data complexity increases and there is more demand from business teams for better data visualisation.
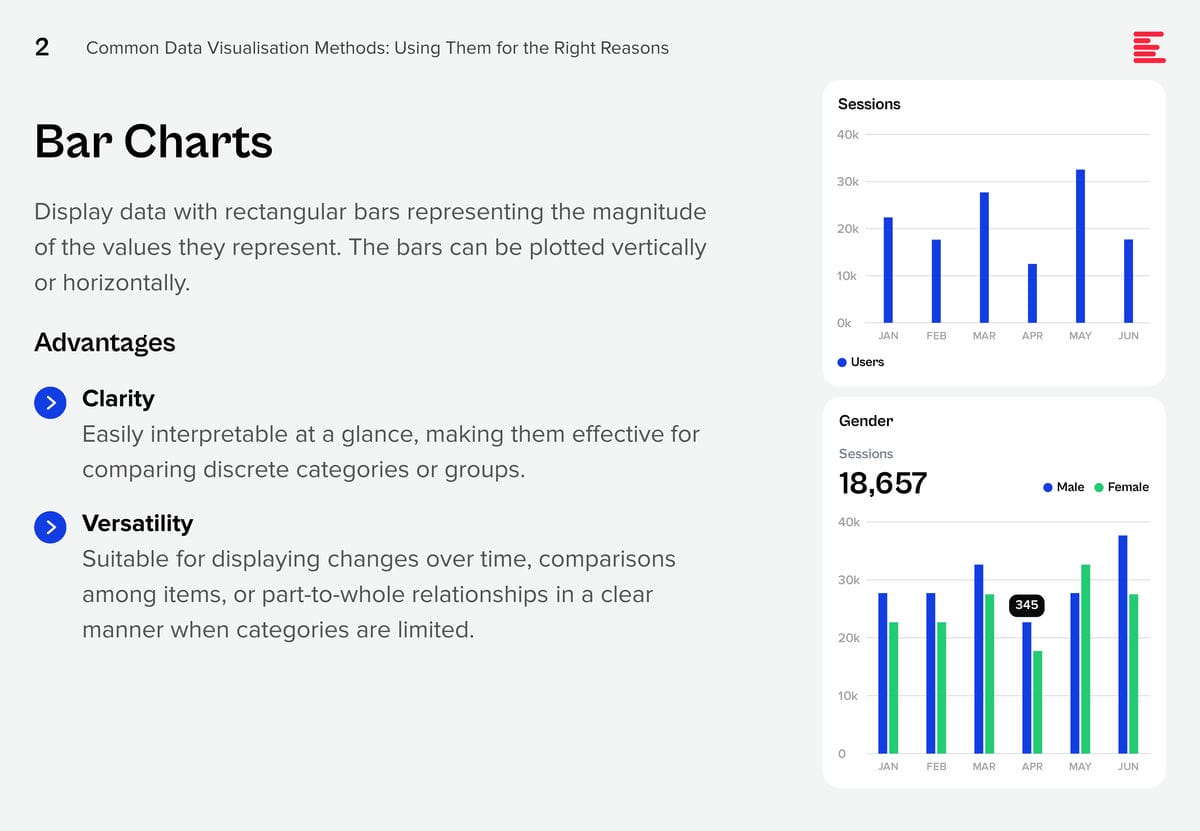
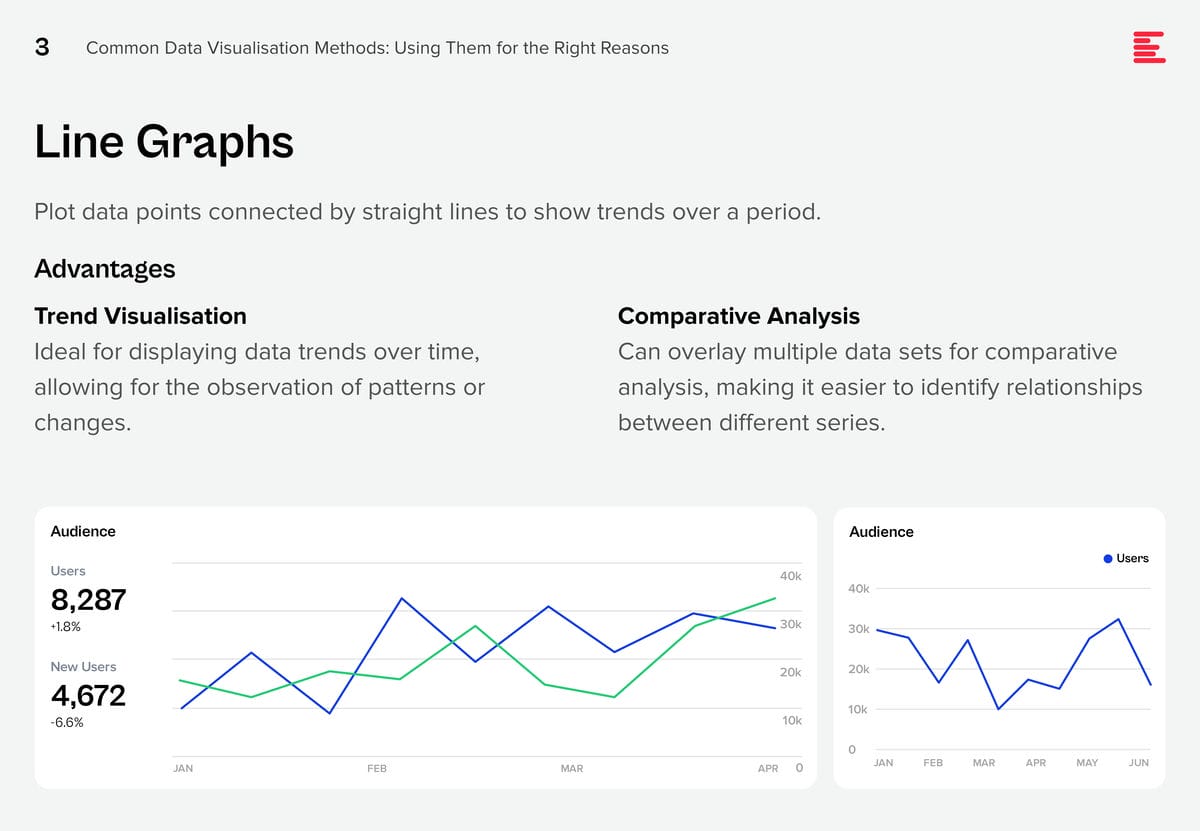
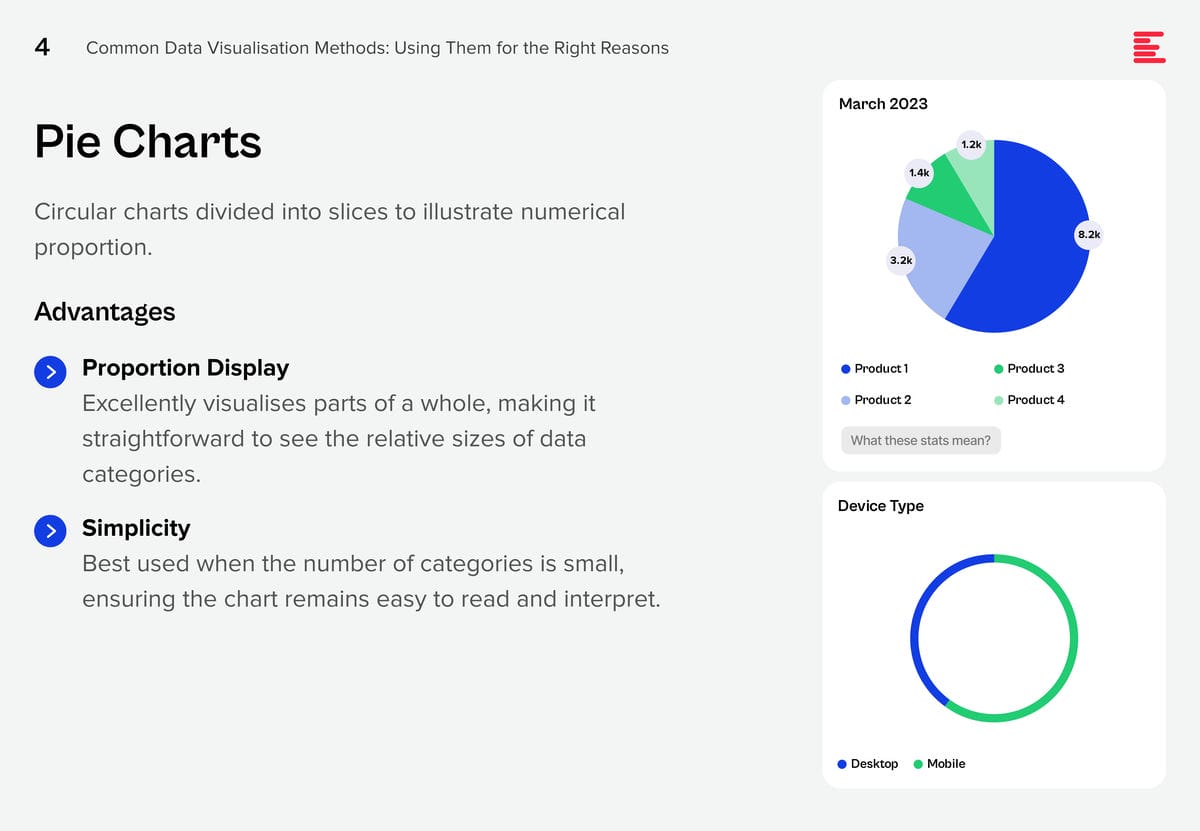
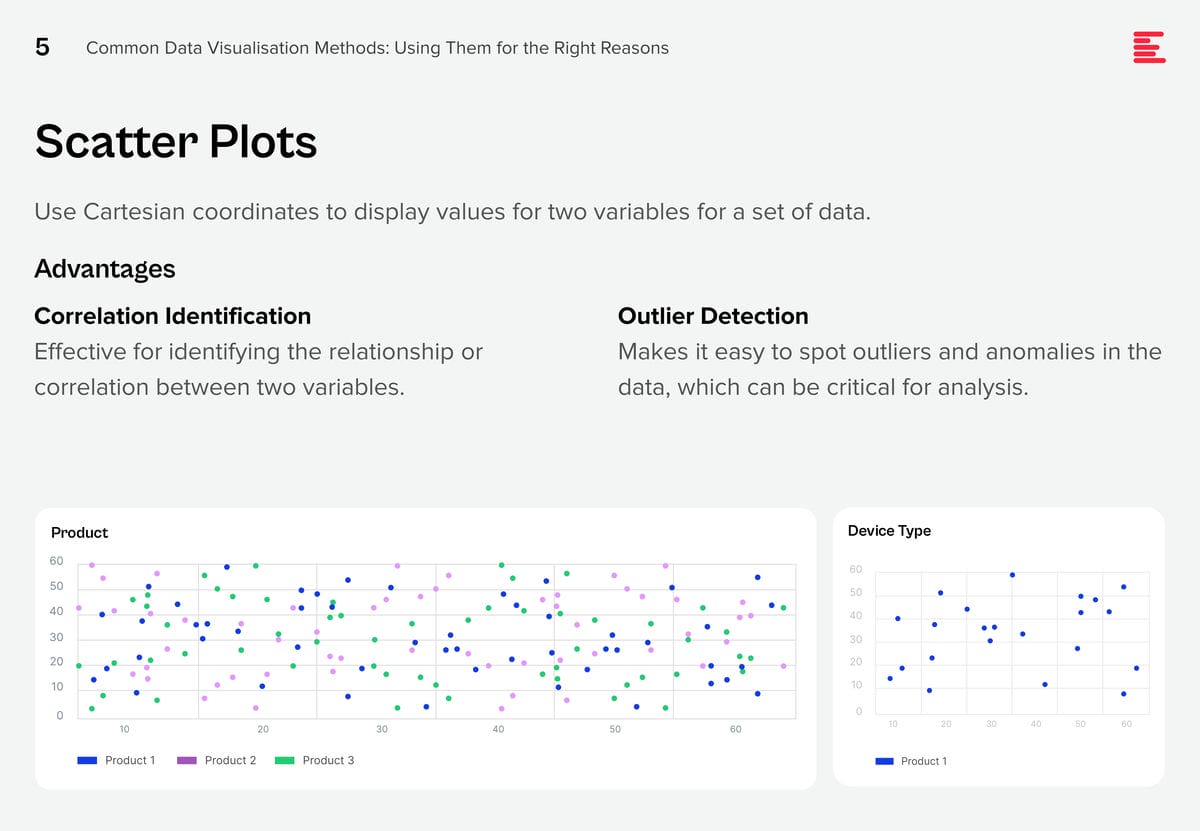
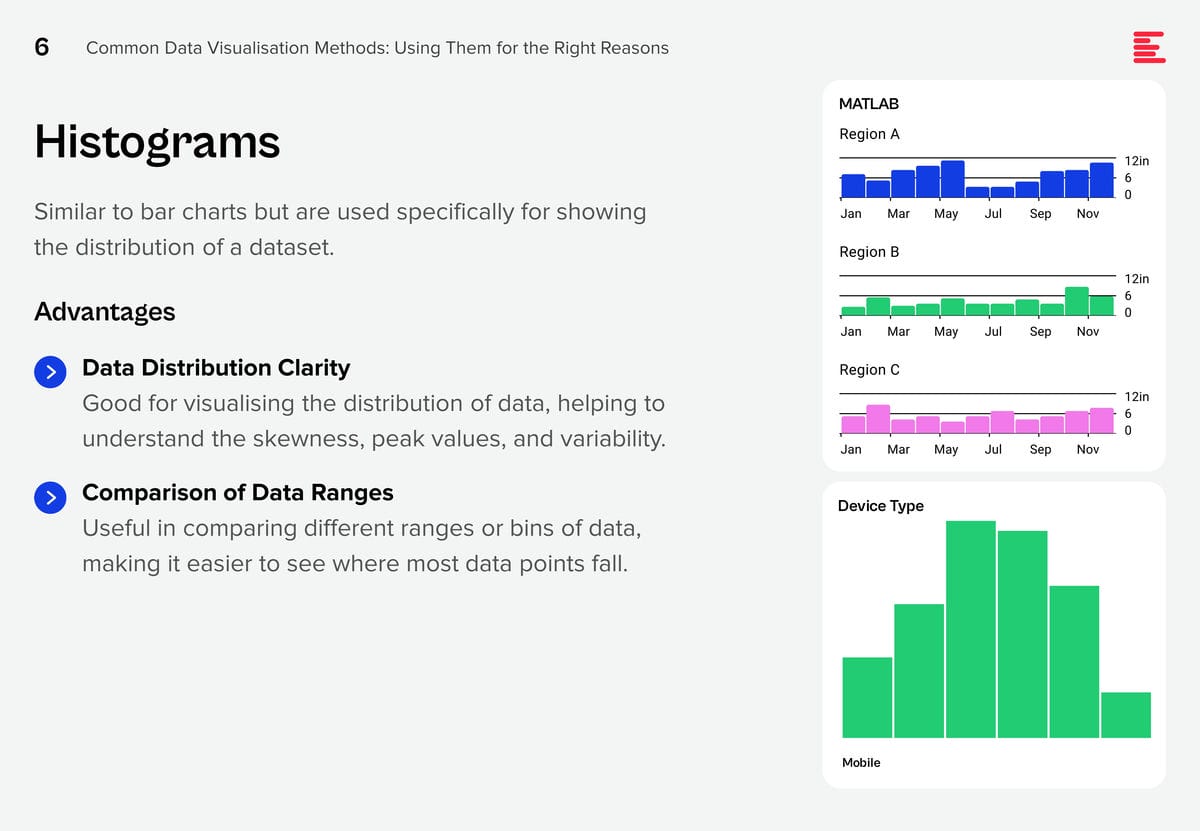
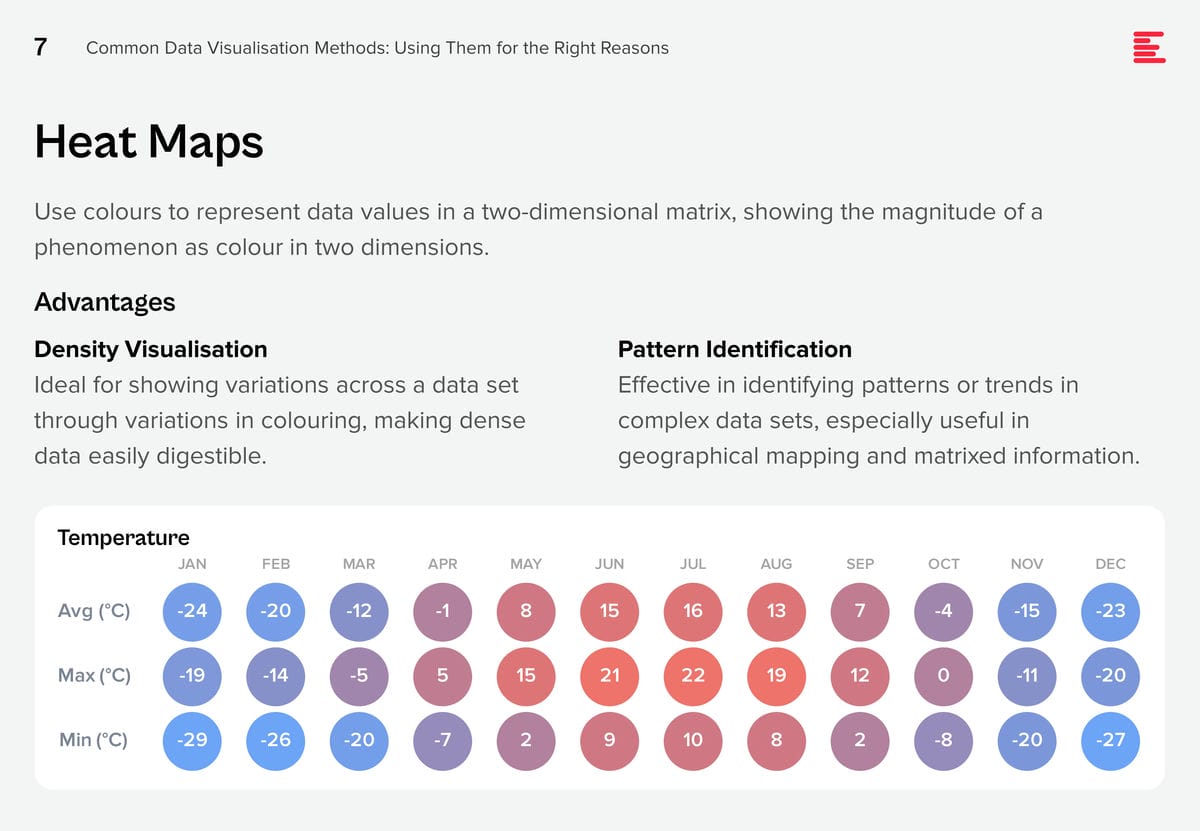
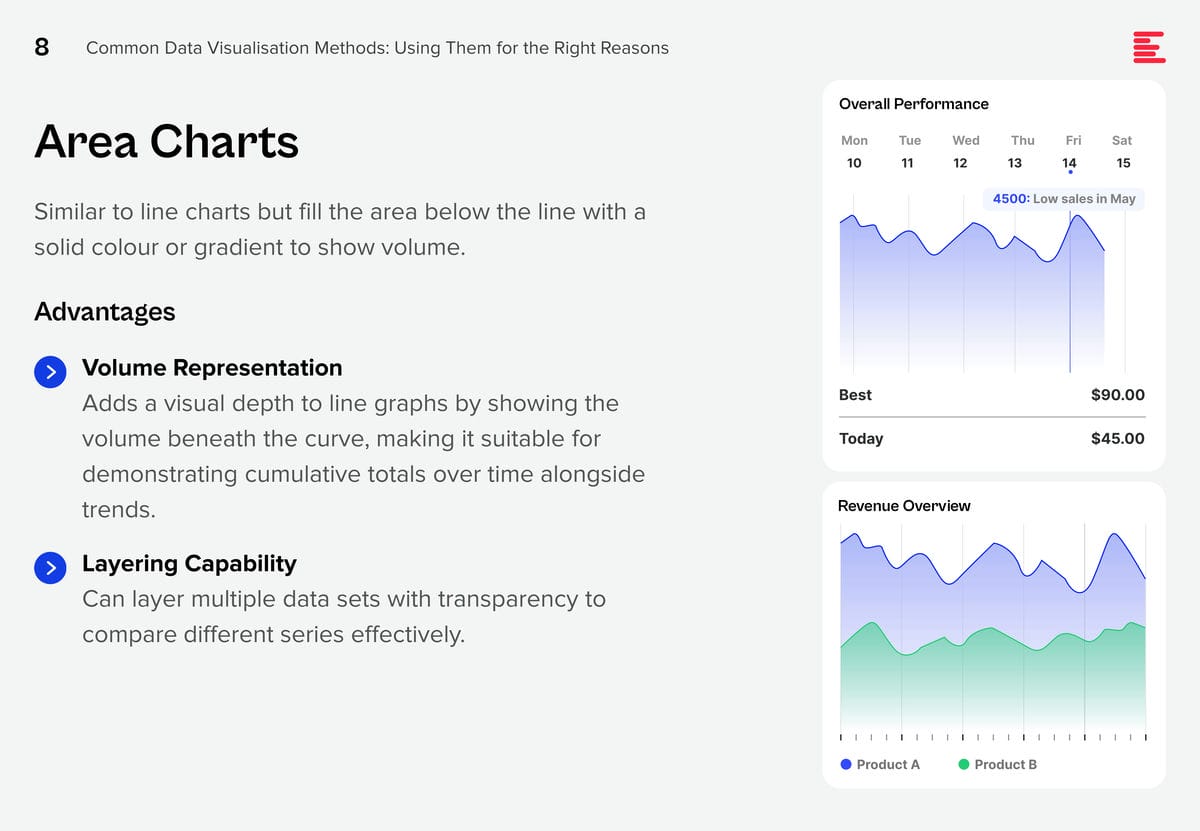
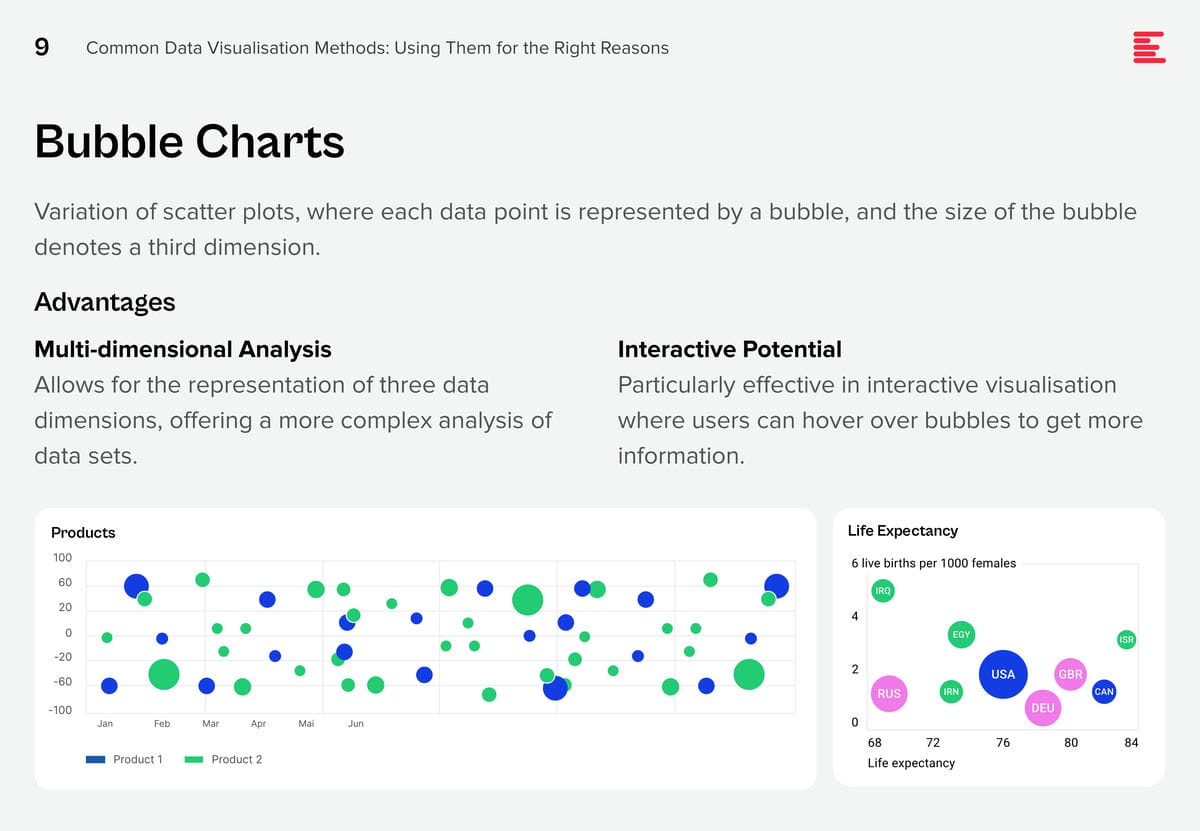
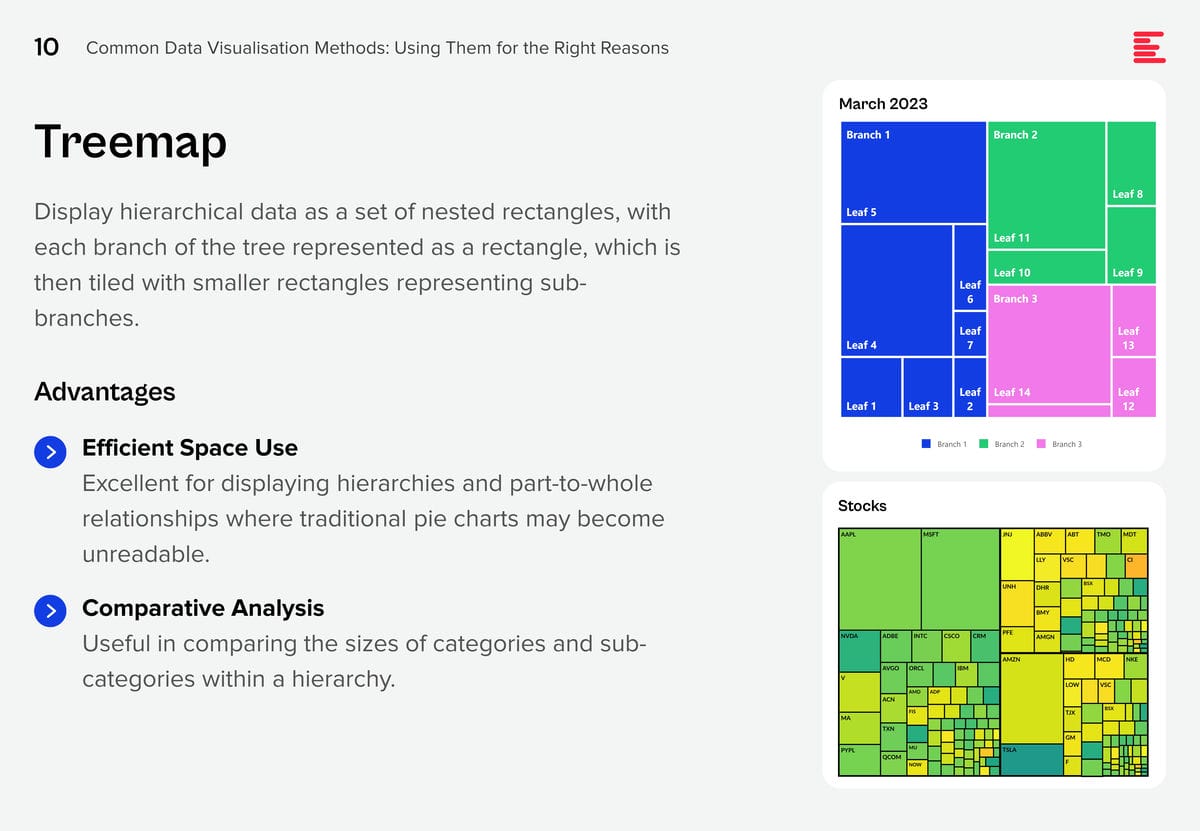
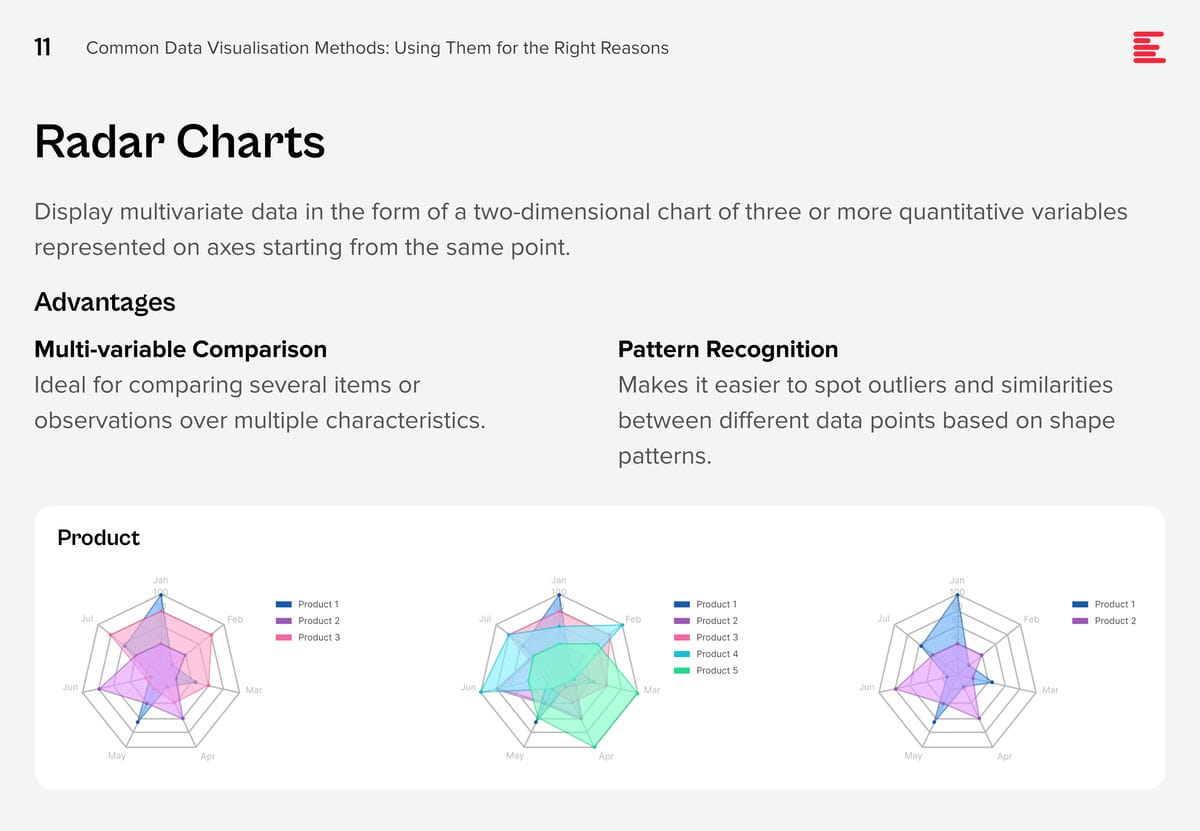


Download Common Data Visualisation Methods as a PDF
Add These to Your Data Visualisation Repertoire
There are additional visualisation tools that you should be using to tell a better data story. Each of these visualisation techniques serves specific purposes in data analysis, offering unique advantages for representing data insights.
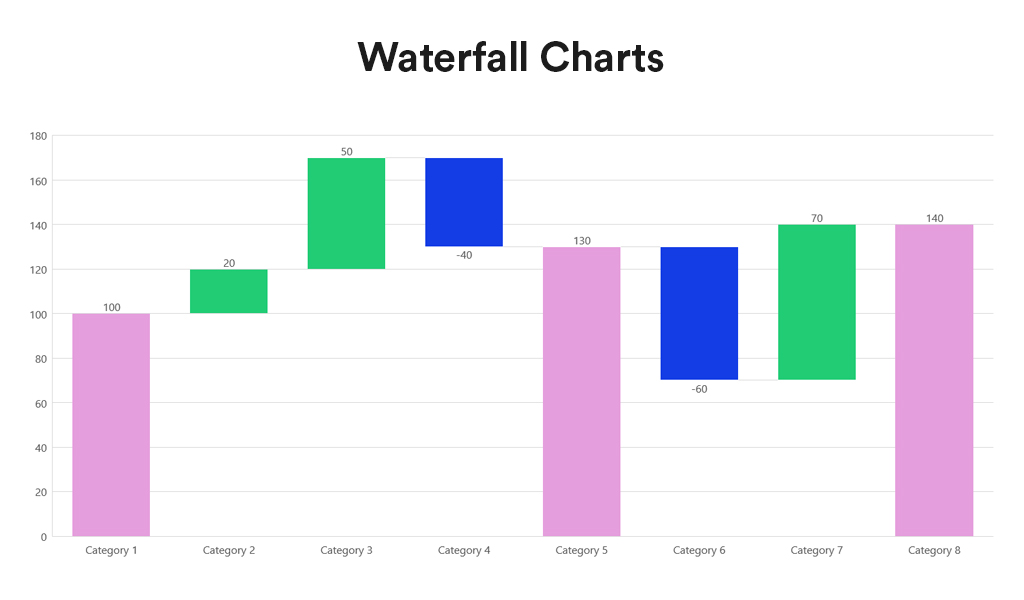
Waterfall charts depict the impact of intermediate positive and negative values on an initial value, often resulting in a final value. They are commonly employed in financial analysis to illustrate the contribution of various factors to a total, making them ideal for visualising step-by-step financial contributions or tracking the cumulative effect of sequentially introduced factors.
Advantages:
- Sequential Analysis. Ideal for understanding the cumulative effect of sequentially introduced positive or negative values.
- Financial Reporting. Commonly used for financial statements to break down the contributions of various elements to a net result, such as revenues, costs, and profits over time.
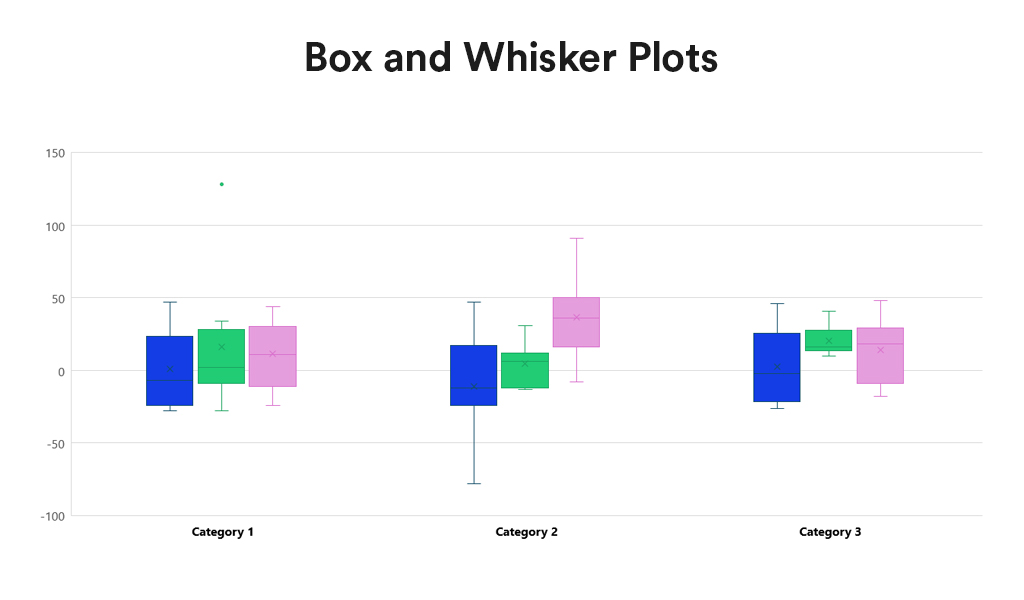
Box and Whisker Plots summarise data distribution using a five-number summary: minimum, first quartile (Q1), median, third quartile (Q3), and maximum. They are valuable for showcasing data sample variations without relying on specific statistical assumptions. Box and Whisker Plots excel in comparing distributions across multiple groups or datasets, providing a concise overview of various statistics.
Advantages:
- Distribution Clarity. Provide a clear view of the data distribution, including its central tendency, variability, and skewness.
- Outlier Identification. Easily identify outliers, offering insights into the spread and symmetry of the data.
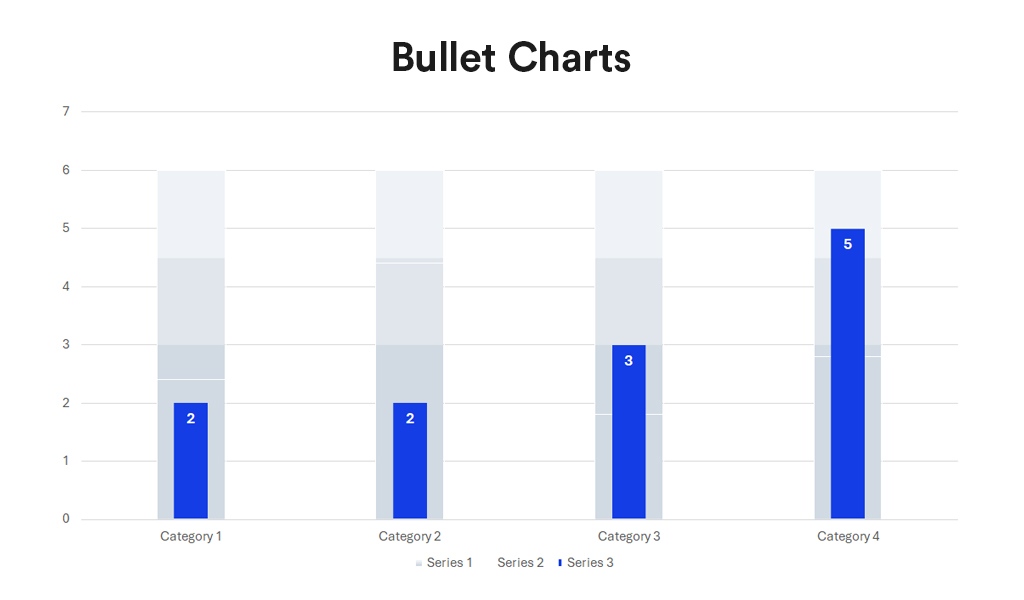
Bullet charts, a bar graph variant, serve as a replacement for dashboard gauges and meters. They showcase a primary measure alongside one or more other measures for context, such as a target or previous period’s performance, often incorporating qualitative ranges like poor, satisfactory, and good. Ideal for performance dashboards with limited space, bullet charts efficiently demonstrate progress towards goals.
Advantages:
- Compactness. Offer a compact and straightforward way to monitor performance against a target.
- Efficiency. More efficient than gauges and meters in dashboard design, as they take up less space and can display more information, making them ideal for comparing multiple measures.
Conclusion
Each data visualisation type has its unique strengths, making it better suited for certain types of data and analysis than others. The key to effective data visualisation lies in matching the visualisation type to your data’s specific needs, considering the story you want, to tell or the insights you aim to glean. Choosing the right data representation helps you to make informed decisions that enhance your data analysis and communication efforts.
Incorporating Waterfall Charts, Box and Whisker Plots, and Bullet Charts into the data visualisation toolkit allows for a broader range of insights to be derived from your data. From analysing financial data, comparing distributions, to tracking performance metrics, these additional types of visualisation can communicate complex data stories clearly and effectively. As with all data visualisation, the key is to choose the type that best matches the organisation’s data story, making it accessible and understandable to the audience.

In my previous Ecosystm Insights, I covered how to choose the right database for the success of any application or project. Often organisations select cloud-based databases for the scalability, flexibility, and cost-effectiveness.
Here’s a look at some prominent cloud-based databases and guidance on the right cloud-based database for your organisational needs.









Click here to download ‘Databases Demystified. Cloud-Based Databases’ as a PDF.
Amazon RDS (Relational Database Service)
Pros.
Managed Service. Automates database setup, maintenance, and scaling, allowing you to focus on application development.
Scalability. Easily scales database’s compute and storage resources with minimal downtime.
Variety of DB Engines. Supports multiple database engines, including MySQL, PostgreSQL, MariaDB, Oracle, and SQL Server.
Cons.
Cost. Can be expensive for larger databases or high-throughput applications.
Complex Pricing. The pricing model can be complex to understand, with costs for storage, I/O, and data transfer.
Google Cloud SQL
Pros.
Fully Managed. Takes care of database management tasks like replication, patch management, and backups.
Integration. Seamlessly integrates with other GCP services, enhancing data analytics and machine learning capabilities.
Security. Offers robust security features, including data encryption at rest and in transit.
Cons.
Limited Customisation. Compared to managing your own database, there are limitations on configurations and fine-tuning.
Egress Costs. Data transfer costs (especially egress) can add up if you have high data movement needs.
Azure SQL Database
Pros.
Highly Scalable. Offers a scalable service that can dynamically adapt to your application’s needs.
Advanced Features. Includes advanced security features, AI-based performance optimisation, and automated updates.
Integration. Deep integration with other Azure services and Microsoft products.
Cons.
Learning Curve. The wide array of options and settings might be overwhelming for new users.
Cost for High Performance. Higher-tier performance levels can become costly.
MongoDB Atlas
Pros.
Flexibility. Offers a flexible document database that is ideal for unstructured data.
Global Clusters. Supports global clusters to improve access speeds for distributed applications.
Fully Managed. Provides a fully managed service, including automated backups, patches, and security.
Cons.
Cost at Scale. While it offers a free tier, costs can grow significantly with larger deployments and higher performance requirements.
Indexing Limitations. Efficient querying requires proper indexing, which can become complex as your dataset grows.
Amazon DynamoDB
Pros.
Serverless. Offers a serverless NoSQL database that scales automatically with your application’s demands.
Performance. Delivers single-digit millisecond performance at any scale.
Durability and Availability. Provides built-in security, backup, restore, and in-memory caching for internet-scale applications.
Cons.
Pricing Model. Pricing can be complex and expensive, especially for read/write throughput and storage.
Learning Curve. Different from traditional SQL databases, requiring time to learn best practices for data modeling and querying.
Selection Considerations
Data Model Compatibility. Ensure the database supports the data model you plan to use (relational, document, key-value, etc.).
Scalability and Performance Needs. Assess whether the database can meet your application’s scalability and performance requirements.
Cost. Understand the pricing model and estimate monthly costs based on your expected usage.
Security and Compliance. Check for security features and compliance with regulations relevant to your industry.
Integration with Existing Tools. Consider how well the database integrates with your current application ecosystem and development tools.
Vendor Lock-in. Be aware of the potential for vendor lock-in and consider the ease of migrating data to other services if needed.
Choosing the right cloud-based database involves balancing these factors to find the best fit for your application’s requirements and your organisation’s budget and skills.

In my last Ecosystm Insights, I outlined various database options available to you. The challenge lies in selecting the right one. Selecting the right database is crucial for the success of any application or project. It involves understanding your data, the operations you’ll perform, scalability requirements, and more. Here is a guide that will walk you through key considerations and steps to choose the most suitable database from the list I shared last week.

Understand Your Data Model
Relational (RDBMS) vs. NoSQL. Choose RDBMS if your data is structured and relational, requiring complex queries and transactions with ACID (Atomicity, Consistency, Isolation, Durability) properties. Opt for NoSQL if you have unstructured or semi-structured data, need to scale horizontally, or require flexibility in your schema design.
Consider the Data Type and Usage
Document Databases are ideal for storing, retrieving, and managing document-oriented information. They’re great for content management systems, ecommerce applications, and handling semi-structured data like JSON, XML.
Key-Value Stores shine in scenarios where quick access to data is needed through a key. They’re perfect for caching and storing user sessions, configurations, or any scenario where the lookup is based on a unique key.
Wide-Column Stores offer flexibility and scalability for storing and querying large volumes of data across many servers, suitable for big data applications, real-time analytics, and high-speed transactions.
Graph Databases are designed for data intensely connected through relationships, ideal for social networks, recommendation engines, and fraud detection systems where relationships between data points are key.
Time-Series Databases are optimised for storing and querying sequential data points indexed in time order. Use them for monitoring systems, IoT applications, and financial trading systems where time-stamped data is critical.
Spatial Databases support spatial data types and queries, making them suitable for geographic information systems (GIS), location-based services, and applications requiring spatial indexing and querying capabilities.
Assess Performance and Scalability Needs
In-Memory Databases like Redis offer high throughput and low latency for scenarios requiring rapid access to data, such as caching, session storage, and real-time analytics.
Distributed Databases like Cassandra or CouchDB are designed to run across multiple machines, offering high availability, fault tolerance, and scalability for applications with global reach and massive scale.
Evaluate Consistency, Availability, and Partition Tolerance (CAP Theorem)
Understand the trade-offs between consistency, availability, and partition tolerance. For example, if your application requires strong consistency, consider databases that prioritise consistency and partition tolerance (CP) like MongoDB or relational databases. If availability is paramount, look towards databases that offer availability and partition tolerance (AP) like Cassandra or CouchDB.
Other Considerations
Check for Vendor Support and Community. Evaluate the support and stability offered by vendors or open-source communities. Established products like Oracle Database, Microsoft SQL Server, and open-source options like PostgreSQL and MongoDB have robust support and active communities.
Cost. Consider both initial and long-term costs, including licenses, hardware, maintenance, and scalability. Open-source databases can reduce upfront costs, but ensure you account for support and operational expenses.
Compliance and Security. Ensure the database complies with relevant regulations (GDPR, HIPAA, etc.) and offers robust security features to protect sensitive data.
Try Before You Decide. Prototype your application with shortlisted databases to evaluate their performance, ease of use, and compatibility with your application’s requirements.
Conclusion
Selecting the right database is a strategic decision that impacts your application’s functionality, performance, and scalability. By carefully considering your data model, type of data, performance needs, and other factors like cost, support, and security, you can identify the database that best fits your project’s needs. Always stay informed about the latest developments in database technologies to make educated decisions as your requirements evolve.

Databases are foundational elements in the tech ecosystem, crucial for managing various data types efficiently. Beyond the traditional relational and NoSQL databases, specialised databases like Time-Series, Spatial, and Document-oriented databases cater to specific needs, enhancing data processing and analysis capabilities. This Ecosystm Insights discusses database categories, offering insights into their functionalities and examples of vendors and products.











Click here to download ‘Databases Demystified – A Guide to Types and Uses’ as a PDF.
Here is a run down of the kinds of databases and their uses for a quick reference.
Relational Databases (RDBMS)
Utilise tables to store data, emphasising relationships among data. They support Structured Query Language (SQL) for data manipulation.
Examples.
- Oracle Database. Feature-rich and scalable, suitable for enterprise-level applications
- MySQL. An Oracle-owned, open-source option popular for web applications
- Microsoft SQL Server. Known for robust data management and analysis features
- PostgreSQL. Offers advanced functionalities, including support for JSON and GIS data
NoSQL Databases
Designed for unstructured data, offering flexibility in data modelling. NoSQL databases are scalable and cater to various data types.
Examples.
- Document-Oriented. MongoDB (flexible JSON-like documents), Couchbase (optimised for mobile and web development)
- Key-Value Stores. Redis (in-memory store used for caching), Amazon DynamoDB (managed, scalable database service)
- Wide-Column Stores. Cassandra (handles large data across many servers), Google Bigtable (high-performance service)
- Graph Databases. Neo4j (manages data in graph structures), Amazon Neptune (managed graph database service).
In-Memory Databases
Store data in RAM instead of on disk, speeding up data retrieval. Ideal for real-time processing and analytics.
Examples.
- Redis. Versatile in-memory data structure store, supporting various data types
- SAP HANA. Accelerates real-time decisions with its high-performance in-memory capabilities
- Oracle TimesTen. Tailored for real-time applications requiring quick data access
NewSQL Databases
Blend the scalability of NoSQL with the ACID guarantees of RDBMS, suitable for modern transactional workloads.
Examples.
- Google Spanner. Offers global-scale transactional consistency
- CockroachDB. Ensures survivability, scalability, and consistency for cloud services
- VoltDB. Combines in-memory speed with NewSQL’s transactional integrity
Distributed Databases
Distribute data across multiple locations to enhance availability, reliability, and scalability.
Examples.
- Cassandra. Ensures robust support for multi-datacentre clusters
- CouchDB. Focuses on ease of use and horizontal scalability
- Riak KV. Prioritises availability and fault tolerance
Object-oriented Databases
Store data as objects, mirroring object-oriented programming paradigms. They seamlessly integrate with object-oriented languages.
Examples.
- db4o. Targets Java and .NET applications, offering an object database solution
- ObjectDB. A powerful Java-oriented object database
- Versant Object Database. Manages complex objects and relationships in enterprise environments
Time-Series Databases
Optimised for storing and managing time-stamped data. Ideal for applications that collect time-based data like IoT, financial transactions, and metrics.
Examples.
- InfluxDB. Open-source database optimised for fast, high-availability storage and retrieval of time-series data in fields like monitoring, analytics, and IoT
- TimescaleDB. An open-source time-series SQL database engineered for fast ingest and complex queries
- Prometheus. A powerful time-series database used for monitoring and alerting, with a strong focus on reliability
Spatial Databases
Specialised in storing and querying spatial data like maps and geometry. They support spatial indexes and queries for efficient processing of location-based data.
Examples.
- PostGIS. An extension to PostgreSQL, adding support for geographic objects and allowing location queries to be run in SQL
- MongoDB. Offers geospatial indexing and querying for handling location-based data efficiently
- Oracle Spatial and Graph. Provides a set of functionalities for managing spatial data and performing advanced spatial queries and analysis
Document Databases
Store data in document formats (e.g., JSON, XML), focusing on the flexibility of data representation. They are schema-less, making them suitable for unstructured and semi-structured data.
Examples.
- MongoDB. Leading document database, offering high performance, high availability, and easy scalability
- CouchDB. Designed for the web, offering a scalable architecture and easy replication features
- Firebase Firestore. A flexible, scalable database for mobile, web, and server development from Firebase and Google Cloud Platform
Conclusion
Understanding the nuances and capabilities of different database types is crucial for selecting the right database that aligns with your application’s needs. From the structured world of RDBMS to the flexible nature of NoSQL, the precision of Time-Series, the geographical prowess of Spatial databases, and the document-oriented approach of Document databases, the landscape is rich and varied. Each database type offers unique features and functionalities, catering to specific data storage and retrieval requirements, enabling developers and businesses to build efficient, scalable, and robust applications.
Look out for my next Ecosystm Insights that will provide guidance on selecting the right database for the right reasons!