

Data analysts play a vital role in today’s data-driven world, providing crucial insights that benefit decision-making processes. For those with a knack for numbers and a passion for uncovering patterns, a career as a data analyst can be both fulfilling and lucrative – it can also be a stepping stone towards other careers in data. While a data analyst focuses on data preparation and visualisation, an AI engineer specialises in creating AI solutions, a machine learning (ML) engineer concentrates on implementing ML models, and a data scientist combines elements of data analysis and ML to derive insights and predictions from data.
Tools, Skills, and Techniques of a Data Analyst
Excel Mastery. Unlocks a powerful toolbox for data manipulation and analysis. Essential skills include using a vast array of functions for calculations and data transformation. Pivot tables become your secret weapon for summarising and analysing large datasets, while charts and graphs bring your findings to life with visual clarity. Data validation ensures accuracy, and the Analysis ToolPak and Solver provide advanced functionalities for statistical analysis and complex problem-solving. Mastering Excel empowers you to transform raw data into actionable insights.
Advanced SQL. While basic skills handle simple queries, advanced users can go deeper with sorting, aggregation, and the art of JOINs to combine data from multiple tables. Common Table Expressions (CTEs) and subqueries become your allies for crafting complex queries, while aggregate functions summarise vast amounts of data. Window functions add another layer of power, allowing calculations within query results. Mastering Advanced SQL empowers you to extract hidden insights and manage data with unparalleled precision.
Data Visualisation. Crafts impactful data stories. These tools empower you to connect to various data sources, transform raw information into a usable format, and design interactive dashboards and reports. Filters and drilldowns allow users to explore your data from different angles, while calculated fields unlock deeper analysis. Parameters add a final touch of flexibility, letting viewers customise the report to their specific needs. With tools Tableau and Power BI, complex data becomes clear and engaging.
Essential Python. This powerful language excels at data analysis and automation. Libraries like NumPy and Pandas become your foundation for data manipulation and wrangling. Scikit-learn empowers you to build ML models, while SciPy and StatsModels provide a toolkit for in-depth statistical analysis. Python’s ability to interact with APIs and web scrape data expands its reach, and its automation capabilities streamline repetitive tasks. With Essential Python, you have the power to solve complex problems.
Automating the Journey. Data analysts can be masters of efficiency, and their skills translate beautifully into AI. Scripting languages like Ansible and Terraform automate repetitive tasks. Imagine streamlining the process of training and deploying AI models – a skill that directly benefits the AI development pipeline. This proficiency in automation showcases the valuable foundation data analysts provide for building and maintaining AI systems.
Developing ML Expertise. Transitioning from data analysis to AI involves building on your existing skills to develop ML expertise. As a data analyst, you may start with basic predictive models. This knowledge is expanded in AI to include deep learning and advanced ML algorithms. Also, skills in statistical analysis and visualisation help in evaluating the performance of AI models.
Growing Your AI Skills
Becoming an AI engineer requires building on a data analysis foundation to focus on advanced skills such as:
- Deep Learning. Learning frameworks like TensorFlow and PyTorch to build and train neural networks.
- Natural Language Processing (NLP). Techniques for processing and analysing large amounts of natural language data.
- AI Ethics and Fairness. Understanding the ethical implications of AI and ensuring models are fair and unbiased.
- Big Data Technologies. Using tools like Hadoop and Spark for handling large-scale data is essential for AI applications.
The Evolution of a Data Analyst: Career Opportunities
Data analysis is a springboard to AI engineering. Businesses crave talent that bridges the data-AI gap. Your data analyst skills provide the foundation (understanding data sources and transformations) to excel in AI. As you master ML, you can progress to roles like:
- AI Engineer. Works on integrating AI solutions into products and services. They work with AI frameworks like TensorFlow and PyTorch, ensuring that AI models are incorporated into products and services in a fair and unbiased manner.
- ML Engineer. Focuses on designing and implementing ML models. They focus on preprocessing data, evaluating model performance, and collaborating with data scientists and engineers to bring models into production. They need strong programming skills and experience with big data tools and ML algorithms.
- Data Scientist. Bridges the gap between data analysis and AI, often involved in both data preparation and model development. They perform exploratory data analysis, develop predictive models, and collaborate with cross-functional teams to solve complex business problems. Their role requires a comprehensive understanding of both data analysis and ML, as well as strong programming and data visualisation skills.
Conclusion
Hone your data expertise and unlock a future in AI! Mastering in-demand skills like Excel, SQL, Python, and data visualisation tools will equip you to excel as a data analyst. Your data wrangling skills will be invaluable as you explore ML and advanced algorithms. Also, your existing BI knowledge translates seamlessly into building and evaluating AI models. Remember, the data landscape is constantly evolving, so continue to learn to stay at the forefront of this dynamic field. By combining your data skills with a passion for AI, you’ll be well-positioned to tackle complex challenges and shape the future of AI.


In my last Ecosystm Insight, I spoke about the importance of data architecture in defining the data flow, data management systems required, the data processing operations, and AI applications. Data Mesh and Data Fabric are both modern architectural approaches designed to address the complexities of managing and accessing data across a large organisation. While they share some commonalities, such as improving data accessibility and governance, they differ significantly in their methodologies and focal points.
Data Mesh
- Philosophy and Focus. Data Mesh is primarily focused on the organisational and architectural approach to decentralise data ownership and governance. It treats data as a product, emphasising the importance of domain-oriented decentralised data ownership and architecture. The core principles of Data Mesh include domain-oriented decentralised data ownership, data as a product, self-serve data infrastructure as a platform, and federated computational governance.
- Implementation. In a Data Mesh, data is managed and owned by domain-specific teams who are responsible for their data products from end to end. This includes ensuring data quality, accessibility, and security. The aim is to enable these teams to provide and consume data as products, improving agility and innovation.
- Use Cases. Data Mesh is particularly effective in large, complex organisations with many independent teams and departments. It’s beneficial when there’s a need for agility and rapid innovation within specific domains or when the centralisation of data management has become a bottleneck.
Data Fabric
- Philosophy and Focus. Data Fabric focuses on creating a unified, integrated layer of data and connectivity across an organisation. It leverages metadata, advanced analytics, and AI to improve data discovery, governance, and integration. Data Fabric aims to provide a comprehensive and coherent data environment that supports a wide range of data management tasks across various platforms and locations.
- Implementation. Data Fabric typically uses advanced tools to automate data discovery, governance, and integration tasks. It creates a seamless environment where data can be easily accessed and shared, regardless of where it resides or what format it is in. This approach relies heavily on metadata to enable intelligent and automated data management practices.
- Use Cases. Data Fabric is ideal for organisations that need to manage large volumes of data across multiple systems and platforms. It is particularly useful for enhancing data accessibility, reducing integration complexity, and supporting data governance at scale. Data Fabric can benefit environments where there’s a need for real-time data access and analysis across diverse data sources.
Both approaches aim to overcome the challenges of data silos and improve data accessibility, but they do so through different methodologies and with different priorities.
Data Mesh and Data Fabric Vendors
The concepts of Data Mesh and Data Fabric are supported by various vendors, each offering tools and platforms designed to facilitate the implementation of these architectures. Here’s an overview of some key players in both spaces:
Data Mesh Vendors
Data Mesh is more of a conceptual approach than a product-specific solution, focusing on organisational structure and data decentralisation. However, several vendors offer tools and platforms that support the principles of Data Mesh, such as domain-driven design, product thinking for data, and self-serve data infrastructure:
- Thoughtworks. As the originator of the Data Mesh concept, Thoughtworks provides consultancy and implementation services to help organisations adopt Data Mesh principles.
- Starburst. Starburst offers a distributed SQL query engine (Starburst Galaxy) that allows querying data across various sources, aligning with the Data Mesh principle of domain-oriented, decentralised data ownership.
- Databricks. Databricks provides a unified analytics platform that supports collaborative data science and analytics, which can be leveraged to build domain-oriented data products in a Data Mesh architecture.
- Snowflake. With its Data Cloud, Snowflake facilitates data sharing and collaboration across organisational boundaries, supporting the Data Mesh approach to data product thinking.
- Collibra. Collibra provides a data intelligence cloud that offers data governance, cataloguing, and privacy management tools essential for the Data Mesh approach. By enabling better data discovery, quality, and policy management, Collibra supports the governance aspect of Data Mesh.
Data Fabric Vendors
Data Fabric solutions often come as more integrated products or platforms, focusing on data integration, management, and governance across a diverse set of systems and environments:
- Informatica. The Informatica Intelligent Data Management Cloud includes features for data integration, quality, governance, and metadata management that are core to a Data Fabric strategy.
- Talend. Talend provides data integration and integrity solutions with strong capabilities in real-time data collection and governance, supporting the automated and comprehensive approach of Data Fabric.
- IBM. IBM’s watsonx.data is a fully integrated data and AI platform that automates the lifecycle of data across multiple clouds and systems, embodying the Data Fabric approach to making data easily accessible and governed.
- TIBCO. TIBCO offers a range of products, including TIBCO Data Virtualization and TIBCO EBX, that support the creation of a Data Fabric by enabling comprehensive data management, integration, and governance.
- NetApp. NetApp has a suite of cloud data services that provide a simple and consistent way to integrate and deliver data across cloud and on-premises environments. NetApp’s Data Fabric is designed to enhance data control, protection, and freedom.
The choice of vendor or tool for either Data Mesh or Data Fabric should be guided by the specific needs, existing technology stack, and strategic goals of the organisation. Many vendors provide a range of capabilities that can support different aspects of both architectures, and the best solution often involves a combination of tools and platforms. Additionally, the technology landscape is rapidly evolving, so it’s wise to stay updated on the latest offerings and how they align with the organisation’s data strategy.


The data architecture outlines how data is managed in an organisation and is crucial for defining the data flow, data management systems required, the data processing operations, and AI applications. Data architects and engineers define data models and structures based on these requirements, supporting initiatives like data science. Before we delve into the right data architecture for your AI journey, let’s talk about the data management options. Technology leaders have the challenge of deciding on a data management system that takes into consideration factors such as current and future data needs, available skills, costs, and scalability. As data strategies become vital to business success, selecting the right data management system is crucial for enabling data-driven decisions and innovation.
Data Warehouse
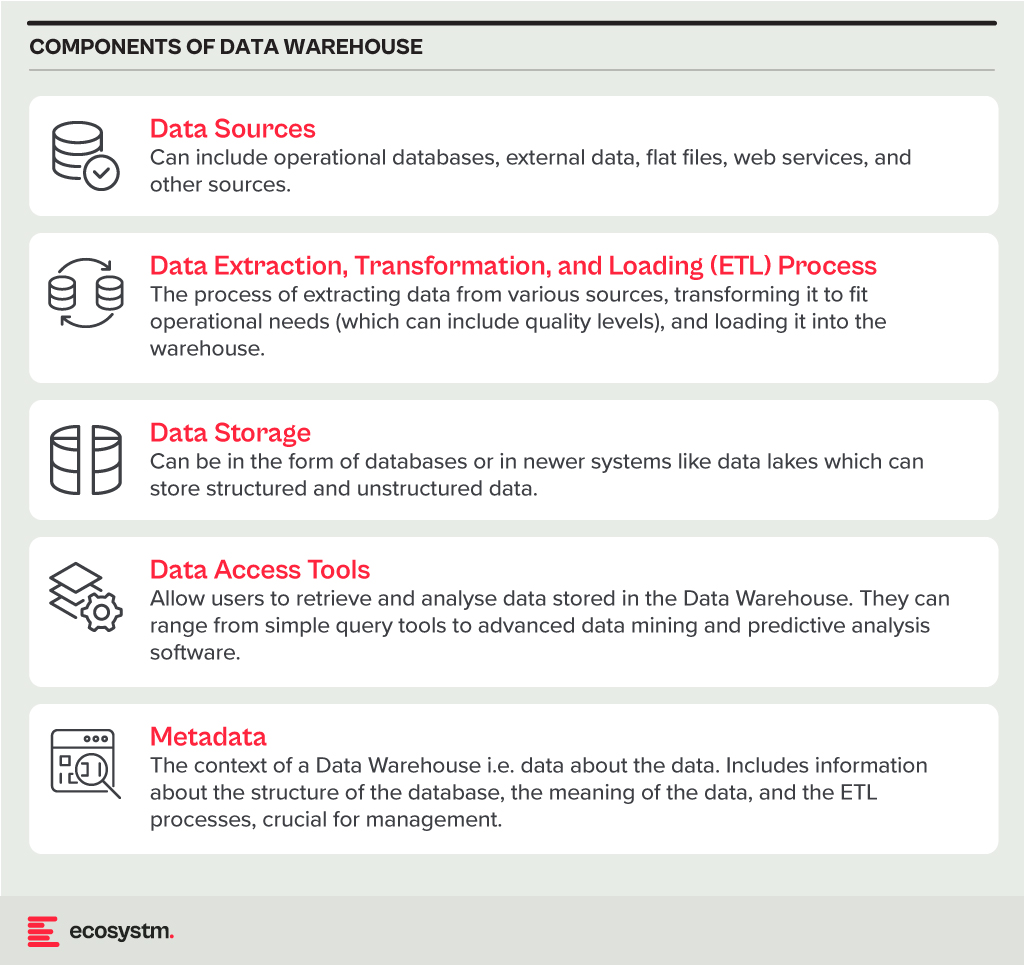
A Data Warehouse is a centralised repository that stores vast amounts of data from diverse sources within an organisation. Its main function is to support reporting and data analysis, aiding businesses in making informed decisions. This concept encompasses both data storage and the consolidation and management of data from various sources to offer valuable business insights. Data Warehousing evolves alongside technological advancements, with trends like cloud-based solutions, real-time capabilities, and the integration of AI and machine learning for predictive analytics shaping its future.
Core Characteristics
- Integrated. It integrates data from multiple sources, ensuring consistent definitions and formats. This often includes data cleansing and transformation for analysis suitability.
- Subject-Oriented. Unlike operational databases, which prioritise transaction processing, it is structured around key business subjects like customers, products, and sales. This organisation facilitates complex queries and analysis.
- Non-Volatile. Data in a Data Warehouse is stable; once entered, it is not deleted. Historical data is retained for analysis, allowing for trend identification over time.
- Time-Variant. It retains historical data for trend analysis across various time periods. Each entry is time-stamped, enabling change tracking and trend analysis.
Benefits
- Better Decision Making. Data Warehouses consolidate data from multiple sources, offering a comprehensive business view for improved decision-making.
- Enhanced Data Quality. The ETL process ensures clean and consistent data entry, crucial for accurate analysis.
- Historical Analysis. Storing historical data enables trend analysis over time, informing future strategies.
- Improved Efficiency. Data Warehouses enable swift access and analysis of relevant data, enhancing efficiency and productivity.
Challenges
- Complexity. Designing and implementing a Data Warehouse can be complex and time-consuming.
- Cost. The cost of hardware, software, and specialised personnel can be significant.
- Data Security. Storing large amounts of sensitive data in one place poses security risks, requiring robust security measures.
Data Lake
A Data Lake is a centralised repository for storing, processing, and securing large volumes of structured and unstructured data. Unlike traditional Data Warehouses, which are structured and optimised for analytics with predefined schemas, Data Lakes retain raw data in its native format. This flexibility in data usage and analysis makes them crucial in modern data architecture, particularly in the age of big data and cloud.
Core Characteristics
- Schema-on-Read Approach. This means the data structure is not defined until the data is read for analysis. This offers more flexible data storage compared to the schema-on-write approach of Data Warehouses.
- Support for Multiple Data Types. Data Lakes accommodate diverse data types, including structured (like databases), semi-structured (like JSON, XML files), unstructured (like text and multimedia files), and binary data.
- Scalability. Designed to handle vast amounts of data, Data Lakes can easily scale up or down based on storage needs and computational demands, making them ideal for big data applications.
- Versatility. Data Lakes support various data operations, including batch processing, real-time analytics, machine learning, and data visualisation, providing a versatile platform for data science and analytics.

Benefits
- Flexibility. Data Lakes offer diverse storage formats and a schema-on-read approach for flexible analysis.
- Cost-Effectiveness. Cloud-hosted Data Lakes are cost-effective with scalable storage solutions.
- Advanced Analytics Capabilities. The raw, granular data in Data Lakes is ideal for advanced analytics, machine learning, and AI applications, providing deeper insights than traditional data warehouses.
Challenges
- Complexity and Management. Without proper management, a Data Lake can quickly become a “Data Swamp” where data is disorganised and unusable.
- Data Quality and Governance. Ensuring the quality and governance of data within a Data Lake can be challenging, requiring robust processes and tools.
- Security. Protecting sensitive data within a Data Lake is crucial, requiring comprehensive security measures.
Data Lakehouse
A Data Lakehouse is an innovative data management system that merges the strengths of Data Lakes and Data Warehouses. This hybrid approach strives to offer the adaptability and expansiveness of a Data Lake for housing extensive volumes of raw, unstructured data, while also providing the structured, refined data functionalities typical of a Data Warehouse. By bridging the gap between these two traditional data storage paradigms, Lakehouses enable more efficient data analytics, machine learning, and business intelligence operations across diverse data types and use cases.
Core Characteristics
- Unified Data Management. A Lakehouse streamlines data governance and security by managing both structured and unstructured data on one platform, reducing organizational data silos.
- Schema Flexibility. It supports schema-on-read and schema-on-write, allowing data to be stored and analysed flexibly. Data can be ingested in raw form and structured later or structured at ingestion.
- Scalability and Performance. Lakehouses scale storage and compute resources independently, handling large data volumes and complex analytics without performance compromise.
- Advanced Analytics and Machine Learning Integration. By providing direct access to both raw and processed data on a unified platform, Lakehouses facilitate advanced analytics, real-time analytics, and machine learning.

Benefits
- Versatility in Data Analysis. Lakehouses support diverse data analytics, spanning from traditional BI to advanced machine learning, all within one platform.
- Cost-Effective Scalability. The ability to scale storage and compute independently, often in a cloud environment, makes Lakehouses cost-effective for growing data needs.
- Improved Data Governance. Centralising data management enhances governance, security, and quality across all types of data.
Challenges
- Complexity in Implementation. Designing and implementing a Lakehouse architecture can be complex, requiring expertise in both Data Lakes and Data Warehouses.
- Data Consistency and Quality. Though crucial for reliable analytics, ensuring data consistency and quality across diverse data types and sources can be challenging.
- Governance and Security. Comprehensive data governance and security strategies are required to protect sensitive information and comply with regulations.
The choice between Data Warehouse, Data Lake, or Lakehouse systems is pivotal for businesses in harnessing the power of their data. Each option offers distinct advantages and challenges, requiring careful consideration of organisational needs and goals. By embracing the right data management system, organisations can pave the way for informed decision-making, operational efficiency, and innovation in the digital age.

Databases are foundational elements in the tech ecosystem, crucial for managing various data types efficiently. Beyond the traditional relational and NoSQL databases, specialised databases like Time-Series, Spatial, and Document-oriented databases cater to specific needs, enhancing data processing and analysis capabilities. This Ecosystm Insights discusses database categories, offering insights into their functionalities and examples of vendors and products.












Click here to download ‘Databases Demystified – A Guide to Types and Uses’ as a PDF.
Here is a run down of the kinds of databases and their uses for a quick reference.
Relational Databases (RDBMS)
Utilise tables to store data, emphasising relationships among data. They support Structured Query Language (SQL) for data manipulation.
Examples.
- Oracle Database. Feature-rich and scalable, suitable for enterprise-level applications
- MySQL. An Oracle-owned, open-source option popular for web applications
- Microsoft SQL Server. Known for robust data management and analysis features
- PostgreSQL. Offers advanced functionalities, including support for JSON and GIS data
NoSQL Databases
Designed for unstructured data, offering flexibility in data modelling. NoSQL databases are scalable and cater to various data types.
Examples.
- Document-Oriented. MongoDB (flexible JSON-like documents), Couchbase (optimised for mobile and web development)
- Key-Value Stores. Redis (in-memory store used for caching), Amazon DynamoDB (managed, scalable database service)
- Wide-Column Stores. Cassandra (handles large data across many servers), Google Bigtable (high-performance service)
- Graph Databases. Neo4j (manages data in graph structures), Amazon Neptune (managed graph database service).
In-Memory Databases
Store data in RAM instead of on disk, speeding up data retrieval. Ideal for real-time processing and analytics.
Examples.
- Redis. Versatile in-memory data structure store, supporting various data types
- SAP HANA. Accelerates real-time decisions with its high-performance in-memory capabilities
- Oracle TimesTen. Tailored for real-time applications requiring quick data access
NewSQL Databases
Blend the scalability of NoSQL with the ACID guarantees of RDBMS, suitable for modern transactional workloads.
Examples.
- Google Spanner. Offers global-scale transactional consistency
- CockroachDB. Ensures survivability, scalability, and consistency for cloud services
- VoltDB. Combines in-memory speed with NewSQL’s transactional integrity
Distributed Databases
Distribute data across multiple locations to enhance availability, reliability, and scalability.
Examples.
- Cassandra. Ensures robust support for multi-datacentre clusters
- CouchDB. Focuses on ease of use and horizontal scalability
- Riak KV. Prioritises availability and fault tolerance
Object-oriented Databases
Store data as objects, mirroring object-oriented programming paradigms. They seamlessly integrate with object-oriented languages.
Examples.
- db4o. Targets Java and .NET applications, offering an object database solution
- ObjectDB. A powerful Java-oriented object database
- Versant Object Database. Manages complex objects and relationships in enterprise environments
Time-Series Databases
Optimised for storing and managing time-stamped data. Ideal for applications that collect time-based data like IoT, financial transactions, and metrics.
Examples.
- InfluxDB. Open-source database optimised for fast, high-availability storage and retrieval of time-series data in fields like monitoring, analytics, and IoT
- TimescaleDB. An open-source time-series SQL database engineered for fast ingest and complex queries
- Prometheus. A powerful time-series database used for monitoring and alerting, with a strong focus on reliability
Spatial Databases
Specialised in storing and querying spatial data like maps and geometry. They support spatial indexes and queries for efficient processing of location-based data.
Examples.
- PostGIS. An extension to PostgreSQL, adding support for geographic objects and allowing location queries to be run in SQL
- MongoDB. Offers geospatial indexing and querying for handling location-based data efficiently
- Oracle Spatial and Graph. Provides a set of functionalities for managing spatial data and performing advanced spatial queries and analysis
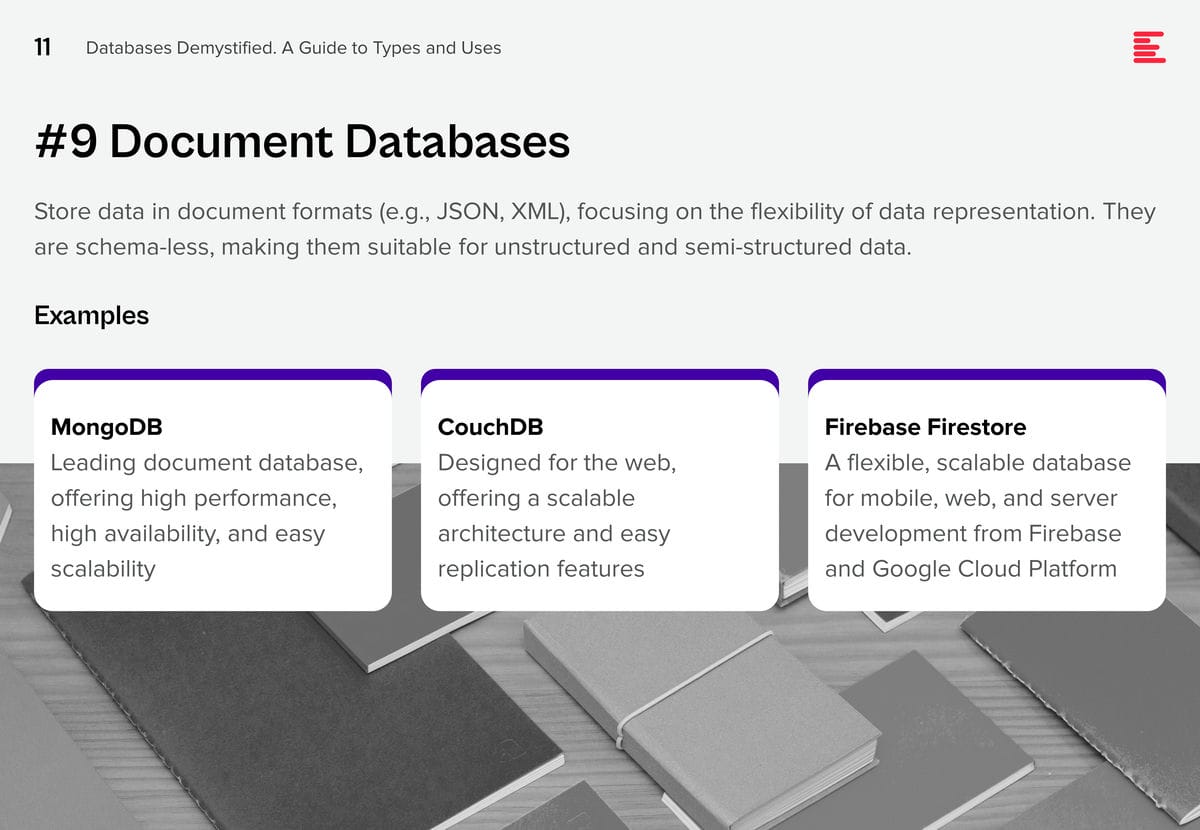
Document Databases
Store data in document formats (e.g., JSON, XML), focusing on the flexibility of data representation. They are schema-less, making them suitable for unstructured and semi-structured data.
Examples.
- MongoDB. Leading document database, offering high performance, high availability, and easy scalability
- CouchDB. Designed for the web, offering a scalable architecture and easy replication features
- Firebase Firestore. A flexible, scalable database for mobile, web, and server development from Firebase and Google Cloud Platform
Conclusion
Understanding the nuances and capabilities of different database types is crucial for selecting the right database that aligns with your application’s needs. From the structured world of RDBMS to the flexible nature of NoSQL, the precision of Time-Series, the geographical prowess of Spatial databases, and the document-oriented approach of Document databases, the landscape is rich and varied. Each database type offers unique features and functionalities, catering to specific data storage and retrieval requirements, enabling developers and businesses to build efficient, scalable, and robust applications.
Look out for my next Ecosystm Insights that will provide guidance on selecting the right database for the right reasons!