

AI is not just reshaping how businesses operate — it’s redefining the CFO’s role at the centre of value creation, risk management, and operational leadership.
As stewards of capital, CFOs must cut through the hype and ensure AI investments deliver measurable business returns. As guardians of risk and compliance, they must shield their organisations from new threats — from algorithmic bias to data privacy breaches with heavy financial and reputational costs. And as leaders of their function, CFOs now have a generational opportunity to modernise finance, champion AI adoption, and build teams ready for an AI-powered future.

LEAD WITH RIGOUR. SAFEGUARD WITH VIGILANCE. CHAMPION WITH VISION.
That’s the CFO playbook for AI success.











Click here to download “AI Stakeholders: The Finance Perspective” as a PDF.
1. Investor & ROI Gatekeeper: Ensuring AI Delivers Value
CFOs must scrutinise AI investments with the same discipline as any major capital allocation.
- Demand Clear Business Cases. Every AI initiative should articulate the problem solved, expected gains (cost, efficiency, accuracy), and specific KPIs.
- Prioritise Tangible ROI. Focus on AI projects that show measurable impact. Start with high-return, lower-risk use cases before scaling.
- Assess Total Cost of Ownership (TCO). Go beyond upfront costs – factor in integration, maintenance, training, and ongoing AI model management.
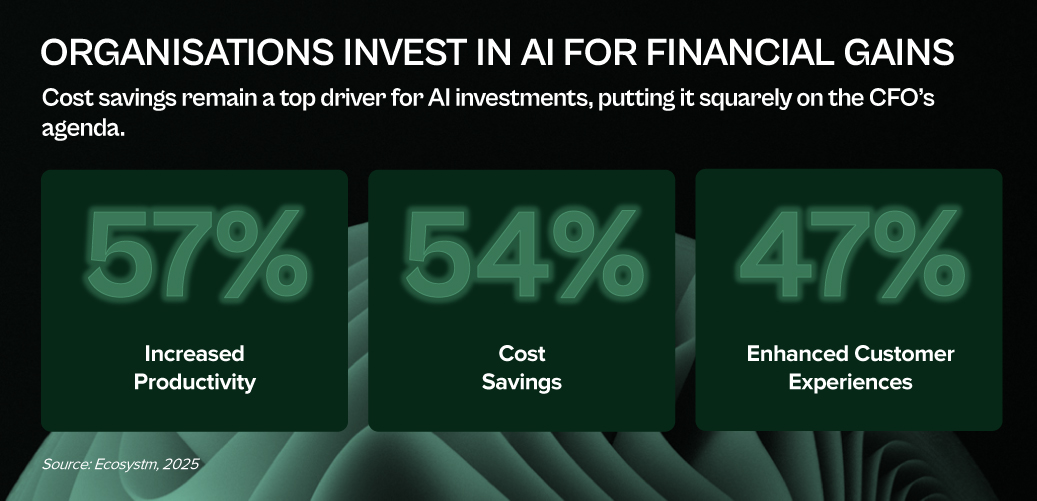
Only 37% of Asia Pacific organisations invest in FinOps to cut costs, boost efficiency, and strengthen financial governance over tech spend.
2. Risk & Compliance Steward: Navigating AI’s New Risk Landscape
AI brings significant regulatory, compliance, and reputational risks that CFOs must manage – in partnership with peers across the business.
- Champion Data Quality & Governance. Enforce rigorous data standards and collaborate with IT, risk, and business teams to ensure accuracy, integrity, and compliance across the enterprise.
- Ensure Data Accessibility. Break down silos with CIOs and CDOs and invest in shared infrastructure that AI initiatives depend on – from data lakes to robust APIs.
- Address Bias & Safeguard Privacy. Monitor AI models to detect bias, especially in sensitive processes, while ensuring compliance.
- Protect Security & Prevent Breaches. Strengthen defences around financial and personal data to avoid costly security incidents and regulatory penalties.
3. AI Champion & Business Leader: Driving Adoption in Finance
Beyond gatekeeping, CFOs must actively champion AI to transform finance operations and build future-ready teams.
- Identify High-Impact Use Cases. Work with teams to apply AI where it solves real pain points – from automating accounts payable to improving forecasting and fraud detection.
- Build AI Literacy. Help finance teams see AI as an augmentation tool, not a threat. Invest in upskilling while identifying gaps – from data management to AI model oversight.
- Set AI Governance Frameworks. Define accountability, roles, and control mechanisms to ensure responsible AI use across finance.
- Stay Ahead of the Curve. Monitor emerging tech that can streamline finance and bring in expert partners to fast-track AI adoption and results.
CFOs: From Gatekeepers to Growth Drivers
AI is not just a tech shift – it’s a CFO mandate. To lead, CFOs must embrace three roles: Investor, ensuring every AI bet delivers real ROI; Risk Guardian, protecting data integrity and compliance in a world of new risks; and AI Champion, embedding AI into finance teams to boost speed, accuracy, and insight.
This is how finance moves from record-keeping to value creation. With focused leadership and smart collaboration, CFOs can turn AI from buzzword to business impact.


A lot has been written and spoken about DeepSeek since the release of their R1 model in January. Soon after, Alibaba, Mistral AI, and Ai2 released their own updated models, and we have seen Manus AI being touted as the next big thing to follow.
DeepSeek’s lower-cost approach to creating its model – using reinforcement learning, the mixture-of-experts architecture, multi-token prediction, group relative policy optimisation, and other innovations – has driven down the cost of LLM development. These methods are likely to be adopted by other models and are already being used today.
While the cost of AI is a challenge, it’s not the biggest for most organisations. In fact, few GenAI initiatives fail solely due to cost.
The reality is that many hurdles still stand in the way of organisations’ GenAI initiatives, which need to be addressed before even considering the business case – and the cost – of the GenAI model.
Real Barriers to GenAI
• Data. The lifeblood of any AI model is the data it’s fed. Clean, well-managed data yields great results, while dirty, incomplete data leads to poor outcomes. Even with RAG, the quality of input data dictates the quality of results. Many organisations I work with are still discovering what data they have – let alone cleaning and classifying it. Only a handful in Australia can confidently say their data is fully managed, governed, and AI-ready. This doesn’t mean GenAI initiatives must wait for perfect data, but it does explain why Agentic AI is set to boom – focusing on single applications and defined datasets.
• Infrastructure. Not every business can or will move data to the public cloud – many still require on-premises infrastructure optimised for AI. Some companies are building their own environments, but this often adds significant complexity. To address this, system manufacturers are offering easy-to-manage, pre-built private cloud AI solutions that reduce the effort of in-house AI infrastructure development. However, adoption will take time, and some solutions will need to be scaled down in cost and capacity to be viable for smaller enterprises in Asia Pacific.
• Process Change. AI algorithms are designed to improve business outcomes – whether by increasing profitability, reducing customer churn, streamlining processes, cutting costs, or enhancing insights. However, once an algorithm is implemented, changes will be required. These can range from minor contact centre adjustments to major warehouse overhauls. Change is challenging – especially when pre-coded ERP or CRM processes need modification, which can take years. Companies like ServiceNow and SS&C Blue Prism are simplifying AI-driven process changes, but these updates still require documentation and training.
• AI Skills. While IT teams are actively upskilling in data, analytics, development, security, and governance, AI opportunities are often identified by business units outside of IT. Organisations must improve their “AI Quotient” – a core understanding of AI’s benefits, opportunities, and best applications. Broad upskilling across leadership and the wider business will accelerate AI adoption and increase the success rate of AI pilots, ensuring the right people guide investments from the start.
• AI Governance. Trust is the key to long-term AI adoption and success. Being able to use AI to do the “right things” for customers, employees, and the organisation will ultimately drive the success of GenAI initiatives. Many AI pilots fail due to user distrust – whether in the quality of the initial data or in AI-driven outcomes they perceive as unethical for certain stakeholders. For example, an AI model that pushes customers toward higher-priced products or services, regardless of their actual needs, may yield short-term financial gains but will ultimately lose to ethical competitors who prioritise customer trust and satisfaction. Some AI providers, like IBM and Microsoft, are prioritising AI ethics by offering tools and platforms that embed ethical principles into AI operations, ensuring long-term success for customers who adopt responsible AI practices.
GenAI and Agentic AI initiatives are far from becoming standard business practice. Given the current economic and political uncertainty, many organisations will limit unbudgeted spending until markets stabilise. However, technology and business leaders should proactively address the key barriers slowing AI adoption within their organisations. As more AI platforms adopt the innovations that helped DeepSeek reduce model development costs, the economic hurdles to GenAI will become easier to overcome.

2024 was a year marked by intense AI-driven innovation. While the hype surrounding AI may have reached a fever pitch, the technology’s transformative potential is undeniable.
The growing interest in AI can be attributed to several factors: the democratisation of AI, with tools and platforms now accessible to businesses of all sizes; AI’s appeal to business leaders, offering actionable insights and process automation; and aggressive marketing by major tech companies, which has amplified the excitement and hype surrounding AI.
2025 will be a year defined by AI, with its transformative impact rippling across industries. However, other geopolitical and social factors will also significantly shape the tech landscape.
Ecosystm analysts Achim Granzen, Alan Hesketh, Audrey William, Clay Miller, Darian Bird, Manish Goenka, Richard Wilkins, Sash Mukherjee, Simona Dimovski, and Tim Sheedy present the key trends and disruptors shaping the tech market in 2025.













Click here to download ‘Key Tech Trends & Disruptors in 2025’ as a PDF
1. Quantum Computing Will Drive Major Transformation in the Tech Industry
Advancements in qubit technology, quantum error correction, and hybrid quantum-classical systems will accelerate breakthroughs in complex problem-solving and machine learning. Quantum communications will revolutionise data security with quantum key distribution, providing nearly unbreakable communication channels. As quantum encryption becomes more widespread, it will replace current cryptographic methods, protecting sensitive data from future quantum-enabled attacks.
With quantum computing threatening encryption standards like RSA and ECC, post-quantum encryption will be critical for data security.
While the full impact of quantum computers is expected within the next few years, 2025 will be pivotal in the transition toward quantum-resistant security measures and infrastructure.

2. Many Will Try, But Few Will Succeed as Platform Companies
Hypergrowth occurs when companies shift from selling products to becoming platform providers. Unlike traditional businesses, platforms don’t own inventory; their value lies in proprietary data and software that connect buyers, sellers, and consumers. Platforms disrupt industries and often outperform legacy businesses, with examples like Uber, Amazon, and Meta, and disruptors like Lemonade in insurance and Wise in international funds transfer.
In 2025, many companies will aim to become platform businesses, with AI seen as a key driver.
They will begin creating platforms and building ecosystems around them – some within existing brands, others launching new ones or even new subsidiaries to seize this opportunity.

3. A Trans-Atlantic Divide Will Emerge in AI Regulation
The EU is poised to continue its rigorous approach to AI regulation, emphasisng ethical considerations and robust governance. This is evident in the recent AI Act, which imposes stringent guidelines and penalties for violations. The EU’s commitment to responsible AI development is likely to lead to a more cautious and controlled innovation landscape.
In contrast, the US, under a new administration, may adopt a more lenient regulatory stance towards AI. This shift could accelerate innovation and foster a more permissive environment for AI development. However, it may also raise concerns about potential risks and unintended consequences.
This divergence in regulatory frameworks could create significant challenges for multinational companies operating in both regions.

4. The Rise of AI-Driven Ecosystem Platforms Will Shape Tech Investments
By 2025, AI-driven ecosystem platforms will dominate tech investments, fueled by technological convergence, market efficiency demands, and evolving regulations. These platforms will integrate AI, IoT, cloud, and data analytics to create seamless, predictive ecosystems that transcend traditional industry boundaries.
Key drivers include advancements in AI, global supply chain disruptions, and rising ESG expectations. Regulatory shifts, such as the EU’s AI Act, will further push for compliant, ethical platforms emphasising transparency and accountability.
For businesses, this shift redefines technology as interconnected ecosystems driving efficiency, innovation, and customer value.

5. AI-Powered Data Fabrics Will be the Foundation for Data-Driven Success
In 2025, AI-powered data fabrics will become a core technology for large organisations.
They will transition from basic data management tools to intelligent systems that deliver value across the entire data lifecycle. Organisations will finally be able to get control of their data governance.
AI’s enhanced role will automate essential data functions, including intelligent data integration and autonomous connection to diverse data sources. AI will also enable proactive data quality management, predicting and preventing errors for improved reliability. AI-driven data fabrics will also offer automated data discovery and mapping, dynamic data quality and governance, intelligent data integration, and enhanced data access and delivery.

6. Focus Will Shift From AI Models to Intelligence Gaps & Performance
While many organisations are investing in AI, only those that started their transformation in 2024 are truly AI-led. Most have become AI-driven through embedded AI in enterprise systems as tech providers continue to evolve their offerings. However, these multi-vendor environments often lack synergy, creating gaps and blind spots.
In 2025, organisations will pause their investments to assess AI capabilities and identify these gaps.
Once they pinpoint the blind spots, investments will refocus not on new AI models, but on areas like model orchestration to manage workflows and ensure peak performance; vendor management to establish unified governance frameworks for flexibility and compliance; and eventually automated AI lifecycle management, with centralised inventories and monitoring to track performance and detect issues like model drift.

7. Specialised Small Language Models Will Gain Traction
GenAI, driven by LLMs, has dominated the spotlight, fueling both excitement and concerns about AI. However, LLM-based GenAI is entering a phase of diminishing returns, both in terms of individual model capabilities and the number of available models. Only a few providers will have the resources to develop LLMs, focusing on a limited number of models.
This will see the increased popularity of small language models (SLMs), that are tailored for a specific purpose, use case, or environment. These models will be developed by startups, organisations, and enterprises with deep domain knowledge and data. They will be fully commercialised driving narrow but distinct ROI.
There will be an increased demand for GPU-as-a-service and SLM-as-a-service, and the platforms which can support these.
8. Multi-agent AI Systems Will Help Manage Complexity and Collaboration
Isolated AI tools that can perform narrow tasks lack the adaptability and coordination required for real-time decision-making. Multi-agent systems, in contrast, consist of decentralised agents that collaborate, share information, and make independent decisions while working toward a common goal. This approach not only improves efficiency but also enhances resilience in rapidly changing conditions.
Early use cases will be in complex environments that require cooperation between multiple stakeholders.
Multi-agent systems will optimise logistics by continuously analysing disruptions and dynamically balancing supply and demand in energy grids. These multi-agent systems will also operate in competitive modes, such as algorithmic trading, ad auctions, and ecommerce recommender systems.

9. Super Apps Will Expand into Rural & Underserved Markets in Asia Pacific
Super apps are set to reshape rural economies, fueled by increased internet access, affordable tech, and heavy government investment in digital infrastructure. Their localised, all-in-one services unlock untapped potential in underserved regions, fostering inclusivity and innovation.
By 2025, super apps will deepen their reach across Asia, integrating communication, payments, and logistics into seamless platforms.
Leveraging affordable mobile devices, cloud-native technologies, and localised services, they will penetrate rural and underserved areas with tailored solutions like agricultural marketplaces, local logistics, and expanded government services. Enterprises investing in agile cloud infrastructure will drive this evolution, bridging the digital divide, boosting economic growth, and enhancing user experiences for millions.

10. Intense Debates Over Remote vs. In-Office Work Will Persist in Asia Pacific
Employers in Asia Pacific will enforce stricter return-to-office policies, linking them to performance metrics and benefits to justify investments in physical spaces and enhance workforce productivity.
However, remote collaboration will remain integral, even for in-office teams.
The push for human-centred tech will grow, focusing on employee well-being and flexibility through AI-powered tools and hybrid platforms. Companies will prioritise enhancing employee experiences with personalised, adaptable workspaces, while office designs will increasingly incorporate biophilic elements, blending nature and technology to support seamless collaboration and remote integration.



Exiting the North-South Highway 101 onto Mountain View, California, reveals how mundane innovation can appear in person. This Silicon Valley town, home to some of the most prominent tech giants, reveals little more than a few sprawling corporate campuses of glass and steel. As the industry evolves, its architecture naturally grows less inspiring. The most imposing structures, our modern-day coliseums, are massive energy-rich data centres, recursively training LLMs among other technologies. Yet, just as the unassuming exterior of the Googleplex conceals a maze of shiny new software, GenAI harbours immense untapped potential. And people are slowly realising that.
It has been over a year that GenAI burst onto the scene, hastening AI implementations and making AI benefits more identifiable. Today, we see successful use cases and collaborations all the time.
Finding Where Expectations Meet Reality
While the data centres of Mountain View thrum with the promise of a new era, it is crucial to have a quick reality check.
Just as the promise around dot-com startups reached a fever pitch before crashing, so too might the excitement surrounding AI be entering a period of adjustment. Every organisation appears to be looking to materialise the hype.
All eyes (including those of 15 million tourists) will be on Paris as they host the 2024 Olympics Games. The International Olympic Committee (IOC) recently introduced an AI-powered monitoring system to protect athletes from online abuse. This system demonstrates AI’s practical application, monitoring social media in real time, flagging abusive content, and ensuring athlete’s mental well-being. Online abuse is a critical issue in the 21st century. The IOC chose the right time, cause, and setting. All that is left is implementation. That’s where reality is met.
While the Googleplex doesn’t emanate the same futuristic aura as whatever is brewing within its walls, Google’s AI prowess is set to take centre stage as they partner with NBCUniversal as the official search AI partner of Team USA. By harnessing the power of their GenAI chatbot Gemini, NBCUniversal will create engaging and informative content that seamlessly integrates with their broadcasts. This will enhance viewership, making the Games more accessible and enjoyable for fans across various platforms and demographics. The move is part of NBCUniversal’s effort to modernise its coverage and attract a wider audience, including those who don’t watch live television and younger viewers who prefer online content.
From Silicon Valley to Main Street
While tech giants invest heavily in GenAI-driven product strategies, retailers and distributors must adapt to this new sales landscape.
Perhaps the promise of GenAI lies in the simple storefronts where it meets the everyday consumer. Just a short drive down the road from the Googleplex, one of many 37,000-square-foot Best Buys is preparing for a launch that could redefine how AI is sold.
In the most digitally vogue style possible, the chain retailer is rolling out Microsoft’s flagship AI-enabled PCs by training over 30,000 employees to sell and repair them and equipping over 1,000 store employees with AI skillsets. Best Buy are positioning themselves to revitalise sales, which have been declining for the past ten quarters. The company anticipates that the augmentation of AI skills across a workforce will drive future growth.

The Next Generation of User-Software Interaction
We are slowly evolving from seeking solutions to seamless integration, marking a new era of User-Centric AI.
The dynamic between humans and software has mostly been transactional: a question for an answer, or a command for execution. GenAI however, is poised to reshape this. Apple, renowned for their intuitive, user-centric ecosystem, is forging a deeper and more personalised relationship between humans and their digital tools.
Apple recently announced a collaboration with OpenAI at its WWDC, integrating ChatGPT into Siri (their digital assistant) in its new iOS 18 and macOS Sequoia rollout. According to Tim Cook, CEO, they aim to “combine generative AI with a user’s personal context to deliver truly helpful intelligence”.
Apple aims to prioritise user personalisation and control. Operating directly on the user’s device, it ensures their data remains secure while assimilating AI into their daily lives. For example, Siri now leverages “on-screen awareness” to understand both voice commands and the context of the user’s screen, enhancing its ability to assist with any task. This marks a new era of personalised GenAI, where technology understands and caters to individual needs.
We are beginning to embrace a future where LLMs assume customer-facing roles. The reality is, however, that we still live in a world where complex issues are escalated to humans.
The digital enterprise landscape is evolving. Examples such as the Salesforce Einstein Service Agent, its first fully autonomous AI agent, aim to revolutionise chatbot experiences. Built on the Einstein 1 Platform, it uses LLMs to understand context and generate conversational responses grounded in trusted business data. It offers 24/7 service, can be deployed quickly with pre-built templates, and handles simple tasks autonomously.
The technology does show promise, but it is important to acknowledge that GenAI is not yet fully equipped to handle the nuanced and complex scenarios that full customer-facing roles need. As technology progresses in the background, companies are beginning to adopt a hybrid approach, combining AI capabilities with human expertise.
AI for All: Democratising Innovation
The transformations happening inside the Googleplex, and its neighbouring giants, is undeniable. The collaborative efforts of Google, SAP, Microsoft, Apple, and Salesforce, amongst many other companies leverage GenAI in unique ways and paint a picture of a rapidly evolving tech ecosystem. It’s a landscape where AI is no longer confined to research labs or data centres, but is permeating our everyday lives, from Olympic broadcasts to customer service interactions, and even our personal devices.
The accessibility of AI is increasing, thanks to efforts like Best Buy’s employee training and Apple’s on-device AI models. Microsoft’s Copilot and Power Apps empower individuals without technical expertise to harness AI’s capabilities. Tools like Canva and Uizard empower anybody with UI/UX skills. Platforms like Coursera offer certifications in AI. It’s never been easier to self-teach and apply such important skills. While the technology continues to mature, it’s clear that the future of AI isn’t just about what the machines can do for us—it’s about what we can do with them. The on-ramp to technological discovery is no longer North-South Highway 101 or the Googleplex that lays within, but rather a network of tools and resources that’s rapidly expanding, inviting everyone to participate in the next wave of technological transformation.

Historically, data scientists have been the linchpins in the world of AI and machine learning, responsible for everything from data collection and curation to model training and validation. However, as the field matures, we’re witnessing a significant shift towards specialisation, particularly in data engineering and the strategic role of Large Language Models (LLMs) in data curation and labelling. The integration of AI into applications is also reshaping the landscape of software development and application design.
The Growth of Embedded AI
AI is being embedded into applications to enhance user experience, optimise operations, and provide insights that were previously inaccessible. For example, natural language processing (NLP) models are being used to power conversational chatbots for customer service, while machine learning algorithms are analysing user behaviour to customise content feeds on social media platforms. These applications leverage AI to perform complex tasks, such as understanding user intent, predicting future actions, or automating decision-making processes, making AI integration a critical component of modern software development.
This shift towards AI-embedded applications is not only changing the nature of the products and services offered but is also transforming the roles of those who build them. Since the traditional developer may not possess extensive AI skills, the role of data scientists is evolving, moving away from data engineering tasks and increasingly towards direct involvement in development processes.
The Role of LLMs in Data Curation
The emergence of LLMs has introduced a novel approach to handling data curation and processing tasks traditionally performed by data scientists. LLMs, with their profound understanding of natural language and ability to generate human-like text, are increasingly being used to automate aspects of data labelling and curation. This not only speeds up the process but also allows data scientists to focus more on strategic tasks such as model architecture design and hyperparameter tuning.
The accuracy of AI models is directly tied to the quality of the data they’re trained on. Incorrectly labelled data or poorly curated datasets can lead to biased outcomes, mispredictions, and ultimately, the failure of AI projects. The role of data engineers and the use of advanced tools like LLMs in ensuring the integrity of data cannot be overstated.
The Impact on Traditional Developers
Traditional software developers have primarily focused on writing code, debugging, and software maintenance, with a clear emphasis on programming languages, algorithms, and software architecture. However, as applications become more AI-driven, there is a growing need for developers to understand and integrate AI models and algorithms into their applications. This requirement presents a challenge for developers who may not have specialised training in AI or data science. This is seeing an increasing demand for upskilling and cross-disciplinary collaboration to bridge the gap between traditional software development and AI integration.
Clear Role Differentiation: Data Engineering and Data Science
In response to this shift, the role of data scientists is expanding beyond the confines of traditional data engineering and data science, to include more direct involvement in the development of applications and the embedding of AI features and functions.
Data engineering has always been a foundational element of the data scientist’s role, and its importance has increased with the surge in data volume, variety, and velocity. Integrating LLMs into the data collection process represents a cutting-edge approach to automating the curation and labelling of data, streamlining the data management process, and significantly enhancing the efficiency of data utilisation for AI and ML projects.
Accurate data labelling and meticulous curation are paramount to developing models that are both reliable and unbiased. Errors in data labelling or poorly curated datasets can lead to models that make inaccurate predictions or, worse, perpetuate biases. The integration of LLMs into data engineering tasks is facilitating a transformation, freeing them from the burdens of manual data labelling and curation. This has led to a more specialised data scientist role that allocates more time and resources to areas that can create greater impact.
The Evolving Role of Data Scientists
Data scientists, with their deep understanding of AI models and algorithms, are increasingly working alongside developers to embed AI capabilities into applications. This collaboration is essential for ensuring that AI models are effectively integrated, optimised for performance, and aligned with the application’s objectives.
- Model Development and Innovation. With the groundwork of data preparation laid by LLMs, data scientists can focus on developing more sophisticated and accurate AI models, exploring new algorithms, and innovating in AI and ML technologies.
- Strategic Insights and Decision Making. Data scientists can spend more time analysing data and extracting valuable insights that can inform business strategies and decision-making processes.
- Cross-disciplinary Collaboration. This shift also enables data scientists to engage more deeply in interdisciplinary collaboration, working closely with other departments to ensure that AI and ML technologies are effectively integrated into broader business processes and objectives.
- AI Feature Design. Data scientists are playing a crucial role in designing AI-driven features of applications, ensuring that the use of AI adds tangible value to the user experience.
- Model Integration and Optimisation. Data scientists are also involved in integrating AI models into the application architecture, optimising them for efficiency and scalability, and ensuring that they perform effectively in production environments.
- Monitoring and Iteration. Once AI models are deployed, data scientists work on monitoring their performance, interpreting outcomes, and making necessary adjustments. This iterative process ensures that AI functionalities continue to meet user needs and adapt to changing data landscapes.
- Research and Continued Learning. Finally, the transformation allows data scientists to dedicate more time to research and continued learning, staying ahead of the rapidly evolving field of AI and ensuring that their skills and knowledge remain cutting-edge.
Conclusion
The integration of AI into applications is leading to a transformation in the roles within the software development ecosystem. As applications become increasingly AI-driven, the distinction between software development and AI model development is blurring. This convergence needs a more collaborative approach, where traditional developers gain AI literacy and data scientists take on more active roles in application development. The evolution of these roles highlights the interdisciplinary nature of building modern AI-embedded applications and underscores the importance of continuous learning and adaptation in the rapidly advancing field of AI.


Over the past year, many organisations have explored Generative AI and LLMs, with some successfully identifying, piloting, and integrating suitable use cases. As business leaders push tech teams to implement additional use cases, the repercussions on their roles will become more pronounced. Embracing GenAI will require a mindset reorientation, and tech leaders will see substantial impact across various ‘traditional’ domains.
AIOps and GenAI Synergy: Shaping the Future of IT Operations
When discussing AIOps adoption, there are commonly two responses: “Show me what you’ve got” or “We already have a team of Data Scientists building models”. The former usually demonstrates executive sponsorship without a specific business case, resulting in a lukewarm response to many pre-built AIOps solutions due to their lack of a defined business problem. On the other hand, organisations with dedicated Data Scientist teams face a different challenge. While these teams can create impressive models, they often face pushback from the business as the solutions may not often address operational or business needs. The challenge arises from Data Scientists’ limited understanding of the data, hindering the development of use cases that effectively align with business needs.
The most effective approach lies in adopting an AIOps Framework. Incorporating GenAI into AIOps frameworks can enhance their effectiveness, enabling improved automation, intelligent decision-making, and streamlined operational processes within IT operations.
This allows active business involvement in defining and validating use-cases, while enabling Data Scientists to focus on model building. It bridges the gap between technical expertise and business requirements, ensuring AIOps initiatives are influenced by the capabilities of GenAI, address specific operational challenges and resonate with the organisation’s goals.
The Next Frontier of IT Infrastructure
Many companies adopting GenAI are openly evaluating public cloud-based solutions like ChatGPT or Microsoft Copilot against on-premises alternatives, grappling with the trade-offs between scalability and convenience versus control and data security.
Cloud-based GenAI offers easy access to computing resources without substantial upfront investments. However, companies face challenges in relinquishing control over training data, potentially leading to inaccurate results or “AI hallucinations,” and concerns about exposing confidential data. On-premises GenAI solutions provide greater control, customisation, and enhanced data security, ensuring data privacy, but require significant hardware investments due to unexpectedly high GPU demands during both the training and inferencing stages of AI models.
Hardware companies are focusing on innovating and enhancing their offerings to meet the increasing demands of GenAI. The evolution and availability of powerful and scalable GPU-centric hardware solutions are essential for organisations to effectively adopt on-premises deployments, enabling them to access the necessary computational resources to fully unleash the potential of GenAI. Collaboration between hardware development and AI innovation is crucial for maximising the benefits of GenAI and ensuring that the hardware infrastructure can adequately support the computational demands required for widespread adoption across diverse industries. Innovations in hardware architecture, such as neuromorphic computing and quantum computing, hold promise in addressing the complex computing requirements of advanced AI models.
The synchronisation between hardware innovation and GenAI demands will require technology leaders to re-skill themselves on what they have done for years – infrastructure management.
The Rise of Event-Driven Designs in IT Architecture
IT leaders traditionally relied on three-tier architectures – presentation for user interface, application for logic and processing, and data for storage. Despite their structured approach, these architectures often lacked scalability and real-time responsiveness. The advent of microservices, containerisation, and serverless computing facilitated event-driven designs, enabling dynamic responses to real-time events, and enhancing agility and scalability. Event-driven designs, are a paradigm shift away from traditional approaches, decoupling components and using events as a central communication mechanism. User actions, system notifications, or data updates trigger actions across distributed services, adding flexibility to the system.
However, adopting event-driven designs presents challenges, particularly in higher transaction-driven workloads where the speed of serverless function calls can significantly impact architectural design. While serverless computing offers scalability and flexibility, the latency introduced by initiating and executing serverless functions may pose challenges for systems that demand rapid, real-time responses. Increasing reliance on event-driven architectures underscores the need for advancements in hardware and compute power. Transitioning from legacy architectures can also be complex and may require a phased approach, with cultural shifts demanding adjustments and comprehensive training initiatives.
The shift to event-driven designs challenges IT Architects, whose traditional roles involved designing, planning, and overseeing complex systems. With Gen AI and automation enhancing design tasks, Architects will need to transition to more strategic and visionary roles. Gen AI showcases capabilities in pattern recognition, predictive analytics, and automated decision-making, promoting a symbiotic relationship with human expertise. This evolution doesn’t replace Architects but signifies a shift toward collaboration with AI-driven insights.
IT Architects need to evolve their skill set, blending technical expertise with strategic thinking and collaboration. This changing role will drive innovation, creating resilient, scalable, and responsive systems to meet the dynamic demands of the digital age.
Whether your organisation is evaluating or implementing GenAI, the need to upskill your tech team remains imperative. The evolution of AI technologies has disrupted the tech industry, impacting people in tech. Now is the opportune moment to acquire new skills and adapt tech roles to leverage the potential of GenAI rather than being disrupted by it.

“AI Guardrails” are often used as a method to not only get AI programs on track, but also as a way to accelerate AI investments. Projects and programs that fall within the guardrails should be easy to approve, govern, and manage – whereas those outside of the guardrails require further review by a governance team or approval body. The concept of guardrails is familiar to many tech businesses and are often applied in areas such as cybersecurity, digital initiatives, data analytics, governance, and management.
While guidance on implementing guardrails is common, organisations often leave the task of defining their specifics, including their components and functionalities, to their AI and data teams. To assist with this, Ecosystm has surveyed some leading AI users among our customers to get their insights on the guardrails that can provide added value.
Data Security, Governance, and Bias

- Data Assurance. Has the organisation implemented robust data collection and processing procedures to ensure data accuracy, completeness, and relevance for the purpose of the AI model? This includes addressing issues like missing values, inconsistencies, and outliers.
- Bias Analysis. Does the organisation analyse training data for potential biases – demographic, cultural and so on – that could lead to unfair or discriminatory outputs?
- Bias Mitigation. Is the organisation implementing techniques like debiasing algorithms and diverse data augmentation to mitigate bias in model training?
- Data Security. Does the organisation use strong data security measures to protect sensitive information used in training and running AI models?
- Privacy Compliance. Is the AI opportunity compliant with relevant data privacy regulations (country and industry-specific as well as international standards) when collecting, storing, and utilising data?
Model Development and Explainability
- Explainable AI. Does the model use explainable AI (XAI) techniques to understand and explain how AI models reach their decisions, fostering trust and transparency?
- Fair Algorithms. Are algorithms and models designed with fairness in mind, considering factors like equal opportunity and non-discrimination?
- Rigorous Testing. Does the organisation conduct thorough testing and validation of AI models before deployment, ensuring they perform as intended, are robust to unexpected inputs, and avoid generating harmful outputs?
AI Deployment and Monitoring
- Oversight Accountability. Has the organisation established clear roles and responsibilities for human oversight throughout the AI lifecycle, ensuring human control over critical decisions and mitigation of potential harm?
- Continuous Monitoring. Are there mechanisms to continuously monitor AI systems for performance, bias drift, and unintended consequences, addressing any issues promptly?
- Robust Safety. Can the organisation ensure AI systems are robust and safe, able to handle errors or unexpected situations without causing harm? This includes thorough testing and validation of AI models under diverse conditions before deployment.
- Transparency Disclosure. Is the organisation transparent with stakeholders about AI use, including its limitations, potential risks, and how decisions made by the system are reached?
Other AI Considerations
- Ethical Guidelines. Has the organisation developed and adhered to ethical principles for AI development and use, considering areas like privacy, fairness, accountability, and transparency?
- Legal Compliance. Has the organisation created mechanisms to stay updated on and compliant with relevant legal and regulatory frameworks governing AI development and deployment?
- Public Engagement. What mechanisms are there in place to encourage open discussion and engage with the public regarding the use of AI, addressing concerns and building trust?
- Social Responsibility. Has the organisation considered the environmental and social impact of AI systems, including energy consumption, ecological footprint, and potential societal consequences?
Implementing these guardrails requires a comprehensive approach that includes policy formulation, technical measures, and ongoing oversight. It might take a little longer to set up this capability, but in the mid to longer term, it will allow organisations to accelerate AI implementations and drive a culture of responsible AI use and deployment.

When non-organic (man-made) fabric was introduced into fashion, there were a number of harsh warnings about using polyester and man-made synthetic fibres, including their flammability.
In creating non-organic data sets, should we also be creating warnings on their use and flammability? Let’s look at why synthetic data is used in industries such as Financial Services, Automotive as well as for new product development in Manufacturing.
Synthetic Data Defined
Synthetic data can be defined as data that is artificially developed rather than being generated by actual interactions. It is often created with the help of algorithms and is used for a wide range of activities, including as test data for new products and tools, for model validation, and in AI model training. Synthetic data is a type of data augmentation which involves creating new and representative data.
Why is it used?
The main reasons why synthetic data is used instead of real data are cost, privacy, and testing. Let’s look at more specifics on this:
- Data privacy. When privacy requirements limit data availability or how it can be used. For example, in Financial Services where restrictions around data usage and customer privacy are particularly limiting, companies are starting to use synthetic data to help them identify and eliminate bias in how they treat customers – without contravening data privacy regulations.
- Data availability. When the data needed for testing a product does not exist or is not available to the testers. This is often the case for new releases.
- Data for testing. When training data is needed for machine learning algorithms. However, in many instances, such as in the case of autonomous vehicles, the data is expensive to generate in real life.
- Training across third parties using cloud. When moving private data to cloud infrastructures involves security and compliance risks. Moving synthetic versions of sensitive data to the cloud can enable organisations to share data sets with third parties for training across cloud infrastructures.
- Data cost. Producing synthetic data through a generative model is significantly more cost-effective and efficient than collecting real-world data. With synthetic data, it becomes cheaper and faster to produce new data once the generative model is set up.

Why should it cause concern?
If real dataset contains biases, data augmented from it will contain biases, too. So, identification of optimal data augmentation strategy is important.
If the synthetic set doesn’t truly represent the original customer data set, it might contain the wrong buying signals regarding what customers are interested in or are inclined to buy.
Synthetic data also requires some form of output/quality control and internal regulation, specifically in highly regulated industries such as the Financial Services.
Creating incorrect synthetic data also can get a company in hot water with external regulators. For example, if a company created a product that harmed someone or didn’t work as advertised, it could lead to substantial financial penalties and, possibly, closer scrutiny in the future.
Conclusion
Synthetic data allows us to continue developing new and innovative products and solutions when the data necessary to do so wouldn’t otherwise be present or available due to volume, data sensitivity or user privacy challenges. Generating synthetic data comes with the flexibility to adjust its nature and environment as and when required in order to improve the performance of the model to create opportunities to check for outliers and extreme conditions.

AI has become intrinsic to our personal lives – we are often completely unaware of technology’s influence on our daily lives. For enterprises too, tech solutions often come embedded with AI capabilities. Today, an organisation’s ability to automate processes and decisions is often dependent more on their desire and appetite for tech adoption, than the technology itself.
In 2022 the key focus for enterprises will be on being able to trust their Data & AI solutions. This will include trust in their IT infrastructure, architecture and AI services; and stretch to being able to participate in trusted data sharing models. Technology vendors will lead this discussion and showcase their solutions in the light of trust.
Read what Ecosystm analysts, Darian Bird, Niloy Mukherjee, Peter Carr and Tim Sheedy think will be the leading Data & AI trends in 2022.









Click here to download Ecosystm Predicts: The Top 5 Trends for Data & AI in 2022 as PDF
